MT-Nábytek.cz je nábytkářská jednička na českém e-commerce trhu. Co když její zákazníci častěji nakupují těsně před ukončením akční nabídky? Pak můžeme v posledních dnech navyšovat bidy a zvýšit tržby z akcí. Přečtěte si druhý díl našeho seriálu o automatizaci bidování v AdWords!

Náš klient pravidelně v akčním období zlevňuje svoje produkty. Podle náhodného zkoumání se zdálo, že více transakcí proběhne těsně před koncem akce. Pokud by tomu tak skutečně bylo, mohli bychom zjištění využít a akce těsně před koncem nabidovat. Proto jsme se rozhodli, že se na data podíváme blíže a prozkoumáme průběhy akcí, zda nevykazují společný vzorec chování.
Workflow byla následovná:
- zkrácení akce na nejvetší společný počet dní
- normalizace do stejného rozsahu hodnot 0 - 1
- vyhlazení šumu a neužitečných složek signálu
- nalezení společného chování
Analýzy a grafy jsme dělali v Rku. Data jsme si stáhnuli po dnech přes Rkový balíček RGA. Zvolili jsme stahování po dnech, abychom zamezili vzorkování. K dispozici jsme tedy měli celkem 24 datasetů za rok (2015−01−01 až 2016-01-06) pro akce odlišné doby trvání (12 - 22 dní).
1. Zkrácení signálu a převzorkování: interpolace s decimací = fail no. 1
V první řadě bychom si data měli zkrátit na stejnou použitelnou délku, a to ideálně tak, že je od konce neustřihneme.
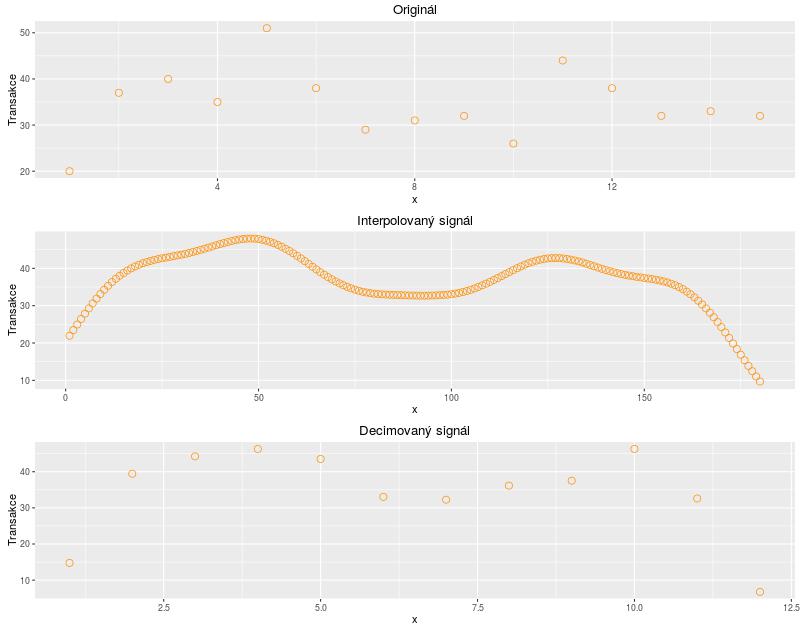
Nejdříve jsme chtěli použít interpolační filtr, kterým zvýšíme počet vzorků a signál natáhneme. Následně ho decimačním filtrem podvzorkujeme tak, abychom dostali požadovanou délku. V Rku se jedná o funkce interp a decimate. Jak ale vypadal výsledek, vidíte na obrázku. Jde o ukázku průběhu transakcí u poslední akce.
U tohoto příkladu interpolace signál natáhneme z 15 vzorků na 180, abychom ho decimací zkrátili na potřebných 12. Konce signálu však kvůli tomu klesají k nule, byť tak původní data nevypadají. Museli bychom zvýšit řád interpolačního filtru, abychom tomu zamezili, ale tím bychom zase zhoršili šum. Tuto metodu jsme proto zamítli.
Místo toho jsme se rozhodli použít aproximaci signálu, kdy jsme signál opět natáhli na délku 180, ale už nedošlo ke zkreslení konců. Na signál jsme navíc použili jednoduchý mediánový filtr, který je vhodný k odstranění náhodného šumu a aspoň trošku jsme tím zjemnili ostré hrany. Když jsme byli s výsledkem spokojení, signál jsme jednoduše podvzorkovali a vybrali pouze každý patnáctý vzorek. Jak je vidět, touto metodou došlo jen k velmi malému zkreslení.
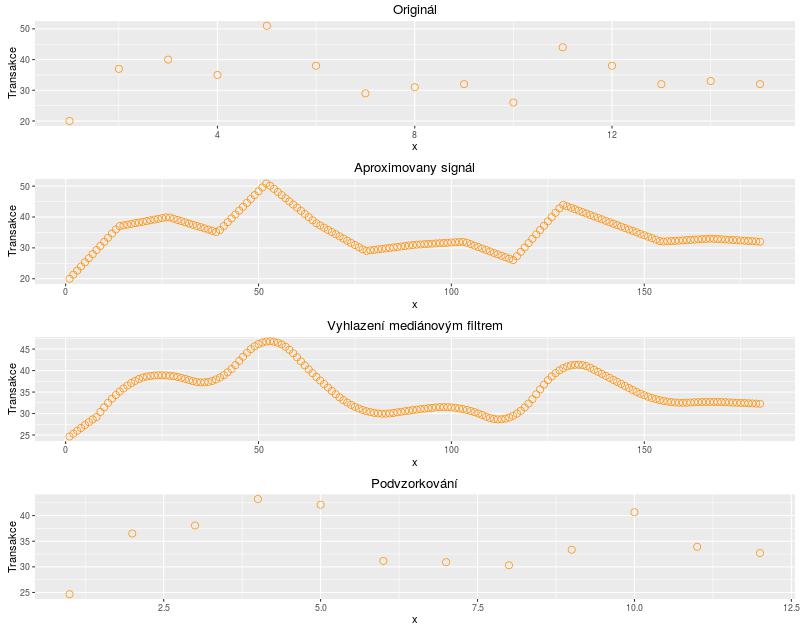
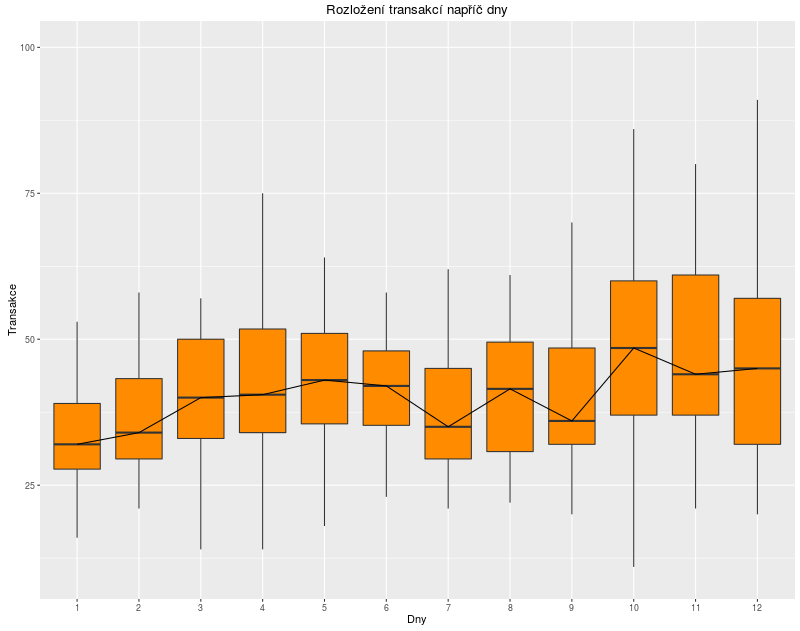
Tímto postupem jsme upravili všechny datasety a získali tak signál ze všech akcí ve správné délce a vyhlazený pro zdůraznění průběhu transakcí. Na následujícím boxplotu vidíme rozložení hodnot napříč dny. Čára uprostřed spojuje mediány jednotlivých dní. Je zřejmé, že z tohoto grafu naši hypotézu o výrazně stoupavé tendenci na konci akcí nepotvrdíme. Na konci akcí je sice vidět větší variabilita v datech, ale jasný nárůst ne.
2. Normalizace
Posunuli jsme všechny hodnoty mezi 0 - 1. Zde nebylo co řešit. Udělali jsme to hlavně z toho důvodu, abychom mohli mezi sebou porovnávat výsledky akcí na odlišné kategorie produktů (například mainstreamové postele v. marginální taburety) nebo v závislosti na sezónnost (vánoční období apod.). Průběhy transakcí sice teoreticky mohou mít podobný vzorec prodejů, ale budou na y-ose od sebe výrazně posunuty.
3. Vyhlazení šumu ve spektrální oblasti a Fourierova transformace = fail no. 2
Snažili jsme se použít k vyhlazení 24 časových řad akcí filtraci pomocí Fourierovy transformace, která signál převádí na harmonické složky neboli spektrum signálu, s nimiž se dá šikovně pracovat. Mluvíme o převodu z časové do frekvenční oblasti, protože tyto harmonické složky charakterizuje právě jejich frekvence.
Nositelem užitečné složky signálu bývá většinou oblast nízkých frekvencí. Proto jsme použili filtraci spektra signálu dolní propustí, respektive horní zádrží, abychom odstranili vyšší frekvence, které bývají většinou nositelkami šumu a neužitečných složek signálu.
Filtrace ve spektrální oblasti má bohužel jednu nevýhodu, a tou je časové zpoždění filtrovaného signálu oproti originálu. Tím, že k němu dochází, bychom přišli o závěrečné dny akcí a dostali bychom z 12 pouze 11 vzorků. Proto jsme k vyhlazení použili nelineární mediánový filtr (viz výše). Fourierova transformace se příliš nehodí, pokud nás zajímají právě okraje signálu. Náš signál byl navíc poměrně krátký.
4. Nalezení společného vzorce dekompozicí signálu = fail no. 3
Předpokládali jsme, že signál je složen z jednotlivých aditivních komponent (Y[t] = T[t] + S[t] + e[t]). Nejdříve jsme proto určili trendovou složku T[t] pomocí plovoucího průměrování, kterou jsme ze signálu odečetli. Poté jsme určili sezónní složku S[t] podobným způsobem a zbytek byla rezidua e[t]. Výsledkem bylo zvlnění trendu a zdá se, že funkce s našimi daty nepracovala dobře. Důvodem pravděpodobně jsou předchozí úpravy signálu, převzorkovávání a vyhlazování.

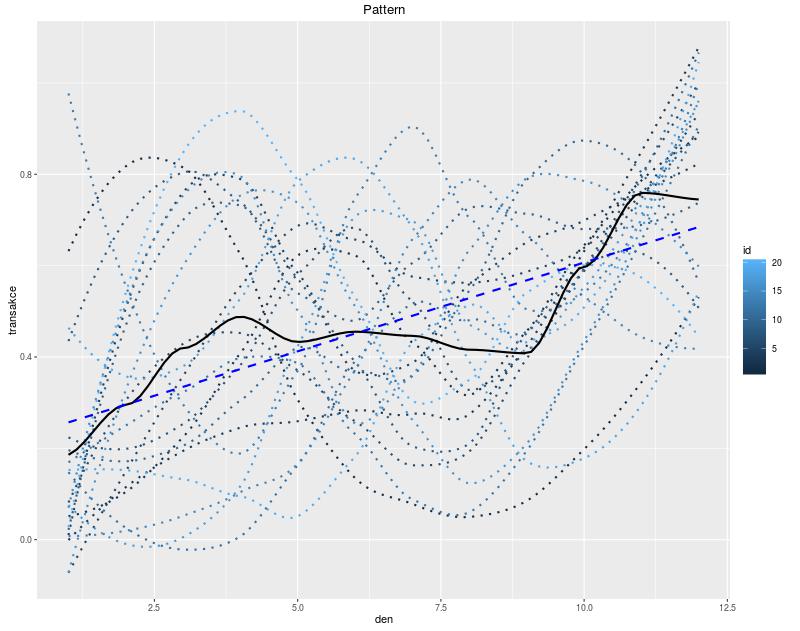
Závěr: poslední dny akce přinášejí vyšší počet transakcí
Po předchozím experimentování jsme se rozhodli, že nám k potvrzení hypotézy bude stačit průměr pro všechny akce (viz obrázek níže). I když průměrná data jsou nepřesná, ke konci je patrný jasný nárůst (viz černá čára na následujícím grafu). To znamená, že jsme potvrdili svou počáteční hypotézu.
Pokud bychom si data nyní exportovali po dnech z grafu do tabulky, můžeme je v AdWords ihned použít jako modifikátor bidu. My jsme si výsledné hodnoty ještě transformovali tak, abychom je získali v rozsahu od -70 do +30 na y-ose (podobné omezení jako má eCPC).
Voilá, vzhůru do bidování!