Agent v datech? Co udělat pro to, aby se v nich neztratil a nepálil zbytečně jak moc svých tokenů, tak computing datového skladu? Tedy: aby nás nebolel účet za náš BigQuery účet?
Na posledním tučňáčím webináři jsme probírali jak doporučení Anthropicu pro práci s agentickou analytikou, tak naše lokální zkušenosti, které jsou vzhledem k možnostem místním firmám bližší. Agentická analytika má dnes dvě nejdůležitější části: konverzační analytiku a vlastní tvorbu přehledů, což beru jako nadstavbu nad konverzační analytikou.

Konverzační analytika umožňuje ptát se na data běžnou řečí, tedy bez používání SQL a dostávat odpovědi opět v běžné řeči.
V teorii to zní skvěle, ale jak píše sám Anthropic “jen napojit Claude na datový sklad může vytvářet falešný pocit přesnosti”. V momentě, kdy to říkají sami tvůrci Claude, bych to nebral na lehkou váhu.
Celkově je totiž potřeba vyřešit tři problémy
1) Nejednoznačnost metrik: uživatel chce zjistit, jaké byly tržby za minulý měsíc, ale v datovém skladu jsou jak tržby namodelované pro manažerský report, tak pro finanční. Navíc není jasné, jestli bude uživatel chtít tržby s DPH, bez DPH, případně jak pracovat s vratkami.
2) Zastarávání dat: je super, když postavíme správné datové základy a všechno vyladíme, ale firma žije dál, a proto je potřeba jak assety, tak agentní „znalosti“ stále aktualizovat.
3) Nedohledání informace: opak k nejednoznačnosti metrik, v tomto případě není problém v tom, že by agent neuměl vybrat mezi více různými metrikami, ale v tom, že není schopen informaci v datech vůbec najít.
Jak ty problémy řešit
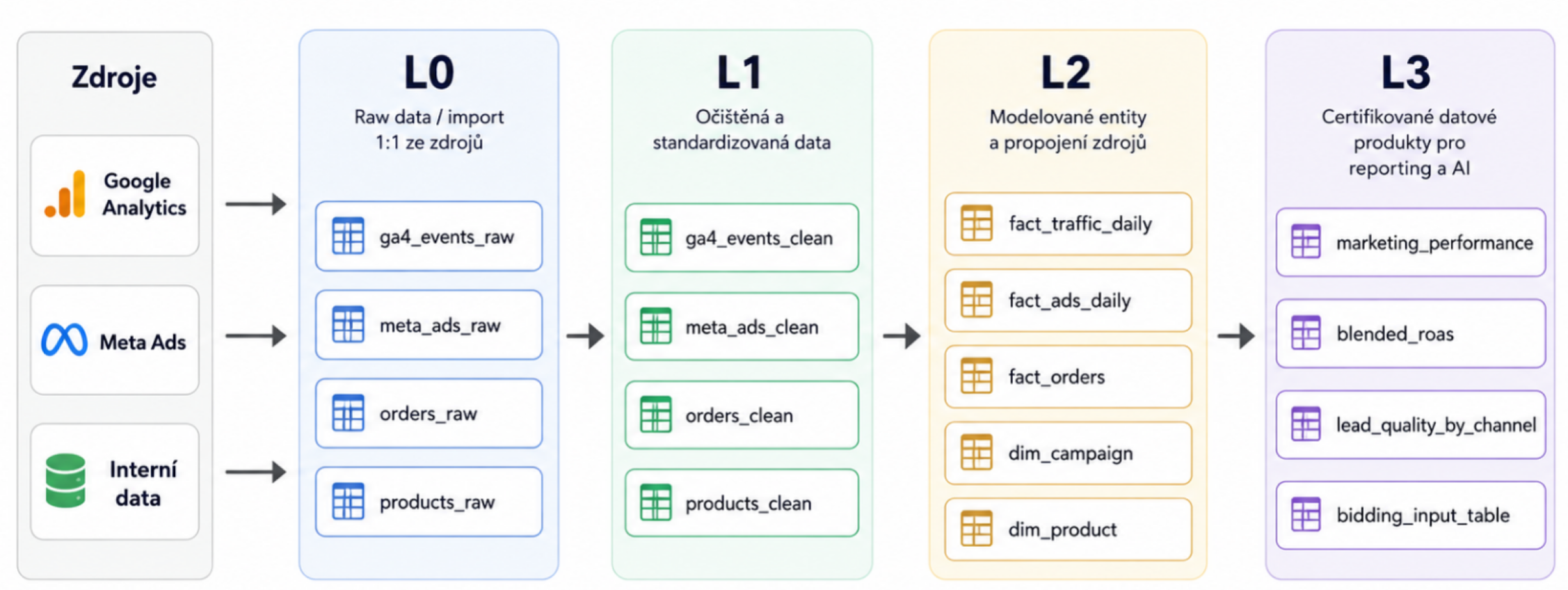
Samotný datový sklad
Dobrá zpráva je, že téměř všechny body byly best practices pro budování datového skladu už dlouho před příchodem analytických agentů. Koncept data lake / data swamp naštěstí po zásluze bloudí po skladišti slepých uliček a vrátili jsme se k pořádně popsaným a dostatečně srozumitelným datovým skladům, ve kterých se lépe vyznají jak lidé, tak agenti.
Data potřebujeme namodelovat nejen efektivně, abychom minimalizovali budoucí náklady spojené se čtením těchto dat, ale hlavně přehledně. Cílem jsou čisté L3, ve kterých se vyzná jak analytik, tak agent.
V rámci datového skladu také řešíme role, maskování dat a nastavování limitů. Tedy omezení dat, ke kterým by agent měl a neměl mít přístup, ať už z hlediska legálnosti (osobní identifikační údaje), protože nám přijdou příliš citlivé, nebo proto, že ještě nejsou připravená a nechceme, aby je zbytečně prolézal a pálil na nich nejen tokeny. Čím menší hrací pole pro agenta vytyčíme, tím lepší a levnější odpovědi budeme dostávat.
Datové sklady téměř vždycky stavíme v BigQuery. Důvod je jednoduchý: jediné přímé napojení na Google Analytics. Pokud firma už nějaký datový sklad má jinde (Microsoft / Amazon stack, tedy Fabric, nebo Redshift), rozvíjíme ten existující, ale minimálně streamu z BigQuery se nevyhneme, pokud nechceme jen omezená data přes GA API.
Na modelování dat je pak industry standard dbt. V momentě, kdy pracujeme s BigQuery, tak většinou používáme Dataform, který je součástí Google Cloud Platform. Každopádně nám přijde dobré stavět vše modulárně, abychom kdykoliv mohli část infrastruktury vyměnit.
Sémantická vrstva
Jeden z mála overhyped přístupů k práci s daty z posledních let, který je v agentní době stále aktuální. Sémantická vrstva je ve své podstatě hrozně jednoduchý koncept. V podstatě se jedná o výkladový slovník (pozor neplést s data dictionary, který má se sémantickou vrstvou velký překryv, ale přeci jen je něco trochu jiného). Na jednom místě jsou namapované analyticky pojmenované metriky na reálné byznysové metriky, vysvětlený jejich výpočet, definovaný povolený rozpad (můžeme marketingové náklady rozpadat pouze na zdroj / kampaň, nebo je máme namodelované i na úroveň produktu či zákazníka) a také informace o tom, s čím je můžeme spojovat, aby to v našem modelu stále dávalo smysl.
Sémantickou vrstvu většinou zpracováváme v cube.js. I tady opět platí, že se snažíme preferovat open source projekty, a hlavní za nás je, aby bylo možné jednotlivé komponenty modulárně vyměnit. Vyhnout se například tomu, abychom byli zamčení ve vizualizačních nástrojích, které se často snaží, aby si firmy budovaly sémantickou vrstvu přímo v jejich prostředí.
Datový katalog
Tím ukončujeme svatou trojici přípravy datového skladu na agentickou analytiku. Dobrý datový sklad by měl minimálně obsahovat informace o tom, kdo je za metriku zodpovědný, jestli obsahuje osobní identifikační údaje, jak často se aktualizuje a jak vypadá její lineage (odkud se bere, jak se počítá). Může to vypadat, že datový sklad je z té trojice nejméně důležitý, ale i tak je nedílnou součástí.
V jednom z největších e-commerce projektů v České republice teď testují agentickou analytiku bez sémantické vrstvy a datového katalogu (čistě s velmi solidně připraveným datovým skladem). Na dotaz, jak jsou spokojení s procentuální kvalitou odpovědí, sdělili, že při těch pár testovacích pokusech super. Jen při jednom dotazu agent nezjistil, že dává data za celou skupinu, a ne jen za českou část. Což je naštěstí dostatečně velká chyba, aby si jí všiml téměř každý. Tak jako tak jde přesně o ten typ chyby, který by měla lineage odstranit.
Na datový katalog používáme Knowledge catalog v rámci GCP, případně z open source řešení DataHub. Možností je ale daleko víc.

A co je cílem? Certifikovaný datový produkt. Popsaná metrika, jak se počítá, jak jde rozpadnout, s jakými dimenzemi zobrazovat, základní pravidla a business kontext, informace o tom, kdo za ni zodpovídá, jak často se aktualizuje, zda obsahuje osobní identifikační údaje, jak vypadá lineage a kde se vlastně nachází.

U spousty věcí svádí nechat si je rovnou vygenerovat Claude Code, tady ale Anthropic celkem důrazně varuje, že to také zkoušeli a výsledky byly dost špatné. Minimálně zatím to vypadá, že ideální postup je nechat si lidmi (klidně ve spolupráci s AI) připravit datové základy a teprve potom pozvat na upravené hřiště agenty.
A co skills?
Toto je upřímně část, které jsme nepřikládali takovou důležitost. Minimálně ne tak velkou, jak naznačuje Anthropic. Ten tvrdí, že před zapojením skills do agentní analytiky nebyli schopni se dostat přes 21% skóre na svých evals (klasifikátorech agentní odpovědi). S postupným zavedením skills se ale dostali až na 95 %. To je však minimálně trochu zavádějící. Anthropic ve svých evals má jako jeden z hlavních bodů, zda se agent jako první doptává sémantické vrstvy a až poté jde případně jinam. Právě to je jedno z chování, které se bez skills nedařilo konzistentně vynucovat.
Samozřejmě, že každý, kdo si s Claude Code hrál déle než jedno odpoledne ví, že skilly nejsou samospásné. Občas se agent rozhodne jinak bez ohledu na to, jak jasně má popsaný doporučený postup.
Pozor, bez udržování skillů up to day už za měsíc poklesla přesnost u Anthropicu z 95 % na 65 %.
--- name: [warehouse-skill] version: [x.y.z] description: "IF the user asks to query [the company]'s data warehouse for any [list of business domains] question — THEN invoke this skill. DO NOT invoke for [adjacent engineering tasks] or questions with no data-warehouse component." --- # [Warehouse] Skill Instructions ## Description The single source of truth for safe and effective [warehouse] querying. Referenced by other skills [listed] for query execution guidance. Act as a Data Analyst, providing strategic insights and data-driven recommendations but seek guidance along the way. **Out-of-scope decisions**: [product areas, etc.] → surface data only, state "decision is [owning team]'s call", do NOT take a position or author code fixes. ## Executing queries Priority: 1. **[Managed connection]** (if available): [query tool] / [schema tool] 2. **[CLI fallback]** (if installed): [default project, fallback project] 3. **Neither** — ask the user to authenticate, then stop # Semantic Layer (REQUIRED first step) The governed semantic layer is the **mandatory default path** for every data question — same numbers as [the BI tool], joins/grain/filters baked in. Raw SQL via the reference docs below is the **fallback**, used only after the semantic-layer path is shown not to cover the ask. ## Required workflow 1. **Load** — [how to load the semantic layer in each runtime, with fallbacks] 2. **Discover** — search measures/dimensions by keyword; **always check segments** (the named canonical population filters — hand-rolled WHERE clauses for these are the dominant wrong-answer mode) 3. **Compile + run** — build the spec → compile to SQL → execute 4. **Fallback** — only if discovery finds no relevant metric or compile fails → raw SQL via `references/*.md` (PART 3 below) > **Don't bail early.** Do NOT fall back to raw SQL on these grounds: > - "[custom date filtering / cohorts]" → [covered by time-dimension specs] > - "[needs a join]" → [the metric layer already encapsulates its joins] > - [3–4 more pre-rebutted excuses agents use to skip the semantic layer] ### Date windows & timezone — decide before you query - **As-of date vs trailing-N days**: [convention for each] - **"Last week/month"** → the last *complete* calendar week/month, not trailing-7/30 - **Timezone default**: [TZ]; [exception for certain reporting rollups] - **Freshness lag**: [some] tables settle late — anchor on MAX(date), not "yesterday"
Ukázka skillu
Co je úplně k ničemu
Jedna z best practices přípravy na agentickou analytiku je query corpus. Ukázky správných SQL s výsledky, notebooky, historické analýzy. Tady jsme my osobně žádné testování vlivu query corpusu na správnost výsledků nedělali, každopádně Anthropic toto testoval údajně dostatečně důkladně a zjistil, že na správnost odpovědi to nemá v podstatě žádný vliv. Agent zkrátka většinou nebyl schopný napárovat nový dotaz na již existující query či analýzu. Navíc analytické best practices jsou součástí skillů a jako takové jsou pro agenta jednodušeji uchopitelné než destilace správného postupu z query corpusu.
95 % a není to málo, Antone Pavloviči?
Přesnost, na kterou se Anthropic dostal, zní dost skvěle. Je potřeba si ale říct, že to je:
1) opravdu pořádně připravený datový sklad, sémantická vrstva, datový katalog i vypimpené skills,
2) Anthropic nejspíš úplně nešetří na interním používání Claude, jeho limitech a modelu - situace, která nejspíš nebude ve všech firmách stejná,
3) i tak je každá dvacátá odpověď špatná, zavádějící.
Anthropic si nejspíš sám tyto limitace uvědomuje, proto uvádí, že agentickou analytiku používají na 95 % business dotazů. Na ty strategicky nejdůležitější otázky tedy nejspíš agenty nepoužívají. To je podle mě správný přístup. Tam, kde to pro mě není naprosto kritické, můžu agenta použít a na odpověď se do nějaké míry spolehnout. Na ty zásadní dotazy však potřebuji minimálně následnou kontrolu.

Co ty validace
Asi jste pochopili, že pouštět agenty do sebelépe připravených dat bez prvotního testování přesnosti a průběžné validace je celkem blbý nápad. Bohužel to ale bývá nejčastější postup. Pro firmy většinou příprava na agenty v datech končí úpravami datového skladu, postavením sémantické vrstvy a spuštěním datového katalogu.
Úplné minimum by mělo být zátěžové testování před spuštěním, při změně modelu nebo rozšířením oblasti, ke které má agent přístup (například budu chtít, aby agent nově analyzoval i skladová data).
A jak by taková offline validace měla vypadat?
Kombinace jednoduše vyhodnotitelných otázek z minulosti (máme na ně připravené odpovědi) a referenčních otázek, při kterých ověřujeme, jak agent rozumí pojmům jako “nejhorší kampaň”, nebo “minulý týden”. Kromě toho také sledujeme, jestli následuje doporučený postup (sémantická vrstva -> odpovídající L3, potřebná kontrola v datovém katalogu), případně analytické best practices, které by dle skillů měl (pokud testujete externího agenta a ne built in, jako je třeba Gemini in BigQuery) dodržovat.
Stejně by se měly sledovat nejen připravené dotazy v rámci offline validace, ale i průběžné agentní výstupy. Teprve ty mohou odhalit slepé skvrny, které by nám jinak unikly. To je ale daleko složitější, protože je potřeba připravit celou infrastrukturu k logování vstupů, agentova postupu, finálního výstupu, případné uživatelské zpětné vazby, ale i hodnocení efektivity dotazů na databázi a hledání vzorců u nepřesných výstupů.
Na webináři jsme se dotkli otázky cloud-based a self-hosted modelů, bezpečnosti a celkově otázky vendor locku. Jakmile záznam upravíme, rádi bychom ho za pár měsíců zveřejnili. Případně pokud si jej chcete pustit ještě v syrové formě, dejte nám vědět a pošleme vám odkaz. Každopádně stay tuned na další tučňáčí webináře a akce. Nezpomalujeme.