Ve čtvrtek 9. 4. se uskutečnil náš jubilejní 10. tučňáčí webinář. Adam s Michaelou se věnovali tématu alertingu — oblasti, která byla vždy aktuální a zajímavá, ale s rychlým nástupem AI agentů nabývá ještě větší důležitosti. Ať už s AI agenty experimentujete, nebo je zatím sledujete jen z povzdálí, nepřestávejte číst. Můžete tak ušetřit spoustu peněz, času a nervů. Dozvíte se například, co alerting vlastně je a jak se liší od dashboardů, proč je důležitý při nasazování AI agentů či jaká technologická magie se skrývá na pozadí.

Potřebujeme alerting? Nestačí dashboard?
Co je vlastně alerting? Jak už samotný název napovídá, jedná se o upozornění — signál, který, má upoutat naši pozornost. Když přijde alert, měli bychom zbystřit, protože se stalo něco, co je potřeba řešit.
Alerty můžeme rozdělit do několika kategorií. Systémové upozorňují na chybu v datech nebo na spadlý konektor. Webové zase na výpadek měření, špatně se spouštějící GTM nebo JavaScript errory. Tomuto technickému alertingu se v článku dále nevěnujeme, ale je třeba zmínit, že tvoří základ celého procesu. Pokud nemáme data v pořádku už na vstupu, jakýkoliv další datový alerting je bezpředmětný.
V tomto článku se zaměříme na alerty datové — data už máme, jsou v pořádku a my chceme být upozorněni na odchylky, problémy, ale i na příležitosti, kterých bychom si při běžném procházení dashboardu nemuseli všimnout.
Ukážeme si to na příkladu:
Představte si, že jste PPC specialista, který spravuje desítky či stovky kampaní napříč několika trhy. Vaše workflow vypadá tak, že přijdete do práce, otevřete si obrovský dashboard se všemi kampaněmi a začnete zkoumat, co by šlo vylepšit, co vypnout, nebo naopak posílit. Jenže množství kampaní a metrik je tak objemné, že dochází k tzv. information overloadu — jste zavalení informacemi natolik, že nevíte, jak se správně rozhodnout. Pracujete pomalu, neefektivně a nemáte čas na rozvojové věci, protože vám tento průzkum „žere“ většinu pracovního dne.
A právě tady přichází na řadu alerting — místo toho, abyste ráno procházeli obrovský dashboard, podíváte se do mailu, Slacku, Asany či jiného systému. Tam na vás bude čekat zpráva s kampaněmi, které si skutečně zaslouží pozornost.

Příklad toho, jak může vypadat notifikační e-mail
Jako specialista ihned víte, co je třeba řešit. Systém za vás totiž udělá tu nudnou a monotónní práci a vy můžete čas věnovat přímo konkrétnímu problému. A ano, v tuto chvíli se už můžete podívat do dashboardu, kde máte všechna potřebná data — už se ale nebudete probírat stovkami kampaní, zaměříte se na omezený vzorek, který skutečně vyžaduje řešení.
Nemusíme se ale držet pouze kampaní a specialistů. Můžeme jít v granularitě i směrem nahoru a takový alert posílat vedoucím týmů, C-levelu či přímo majitelům — samozřejmě s nižší frekvencí a vyšší mírou agregace, aby jim při rozhodování dával smysl.
Z hlediska formy máme velký prostor pro přizpůsobení. Alertovat můžeme prakticky cokoliv a jakkoliv. Alerty je možné segmentovat — každému oddělení chodí jiné upozornění, v jiné formě a podle jiných pravidel. Dokonce je možné, aby každému jednotlivému zaměstnanci chodily jiné alerty v odlišné frekvenci - podle jeho role a potřeb.
Další výhodou alertingu jsou dynamické thresholdy. V dashboardech je zpravidla nastaveno podmíněné formátování ve stylu: „Když kampani klesne ROAS pod hodnotu X, zčervená řádek.“ S pomocí alertingu a přístupu k celému datovému skladu dokážeme tyto hodnoty modelovat dynamicky — ať už sofistikovaně (např. pomocí statických modelů), nebo jednoduše (např. přes klouzavé průměry).
💡Nezapomeňte na efektivní nastavení thresholdu – nechcete aby vám vyskočila změna u kampaně, která přinesla dvě konverze oproti čtyřem z předchozího dne. Takové kampaně tu vždy budou, ale není nutné, aby nám kvůli nim chodil ať už pozitivní, tak negativní alerting.
I když jsou dynamické hodnoty super věc a přinášejí velkou přidanou hodnotu, neměli bychom zanevřít ani na hodnoty statické. Ty se hodí v případě, že máme pevně stanové budgety a daná kampaň nebo kampaně celkově nesmí za žádných okolností utratit více, nebo v případě, že máme z povahy našeho businessu omezenou kapacitu a při velmi úspěšné kampani by hrozilo, že nedokážeme uspokojit poptávku. Takovou situaci si můžeme ukázat na síti kadeřnictví, která má ze své podstaty omezenou kapacitu. Pokud by byla propagace až moc úspěšná, mohlo by nám to uškodit – delší čekací doby by se mohly projevit negativně na naší reputaci nehledě na to, že i když by reklama oslovila potenciální zákazníky, tak by si i kvůli těmto dobám termín nerezervovali, což by se negativně podepsalo na výsledcích kampaně.
Další příklad, kdy vám alerting může zachránit nejen spoustu peněz, ale i reputaci, uvedli Adam s Michaelou na webináři. Jste e-shop, který prodává tenisky. Z ničeho nic se vaše prodeje znásobí, ale záhadným způsobem vám klesne revenue, přestože registrujete rekordní objednávky. V tu chvíli by se vám měly rozeznít všechny nastavené alerty, měly by přijít SMS s maximální prioritou. Co se ale stalo ve skutečnosti? Trvalo pár dní, než se na problém přišlo a ztráty už byly na světě.
Alerting v kontextu AI agentů
Někteří z vás si možná říkají, že tohle mají vyřešené, protože přesně to, co jsem popsal výše, jim už teď dělá AI agent automaticky. A je to validní argument. Je ale potřeba si uvědomit, jak tito AI agenti fungují a že i dnes je nutné jejich výstupy a doporučení validovat.
Alerting je ryze deterministická věc. Pracuje s jasně definovaným kódem a pravidly, díky čemuž poskytuje konzistentní a předvídatelné výstupy. Oproti tomu AI agent deterministický není — stále funguje na principu pravděpodobnosti. I když se AI za poslední měsíce a roky posunulo a stále se posouvá raketovou rychlostí, princip na pozadí zůstává stejný. Výstupy nemusí být konzistentní, agent může halucinovat a ztrácet kontext.

Adam a Michaela v rozpravě nad alertingem
Právě kontext je další bolístkou AI agentů. Pokud máme stovky kampaní s desítkami metrik, pustit na takový dataset AI agenta bude drahé a neefektivní. Samotný akt alertu — přijde nám notifikace — je až posledním krokem, kterému musí předcházet výběr dat. Agenta poté nenapojujeme na celý dataset, ale pouze na výběr, který jsme učinili ryze deterministicky. Tím mu výrazně snížíme potřebný kontext, ušetříme peníze a budeme mít jistotu, že pracuje pouze nad kampaněmi, které to potřebují.
Problém kontextu je obzvlášť znát, pokud máte datový sklad, který není na AI agenty připravený. Mám na mysli především kvalitně zpracovanou sémantickou vrstvu, která je pro správné fungování AI agentů naprosto nezbytná. Pokud takovou vrstvu nemáme, můžeme si pomoci předpočítanými tabulkami, ze kterých bude čerpat jak alerting, tak AI agenti.
A nakonec samotná validace. Pokud AI agenty nasazujete, musíte si ověřit, že vám nelžou a nehalucinují. Vybral agent správné kampaně? Spočítal správně ROAS? Neuniká mu, jak přistoupit k YoY porovnání? Výstupy z alertingu pak můžete porovnávat s výstupy AI agenta a jednoduše zjistit, zda se někde neplete.
Pokud byste si z celého článku měli odnést jednu věc, tak to, že alerting je pevně daná deterministická pojistka k něčemu, co může být nestálé.
Detekce anomálií
Alerting je potřebná a užitečná věc, jejíž výhodou je striktní dodržování nastavených pravidel. Co se ale může jevit jako jasná výhoda, je zároveň i nevýhodou. Případy nebo situace, které nejsou definované našimi pravidly, nám mohou uniknout. Abychom tomu zabránili, používáme něco, čemu říkáme detekce anomálií.
Ta se narozdíl od alertingu neřídí pevně danými pravidly (např. sledování vývoje ROAS v sedmidenním klouzavém průměru), ale detekuje jakoukoliv anomálii v datech, která se odlišuje od běžného chování.
Pro tuto detekci můžeme v základu využít BigQuery ML, který je nejjednodušší volbou, pokud využíváme Google stack — což ve většině případů, i s ohledem na potřebu BigQuery, děláme. Můžeme ale sáhnout i po specializovaných algoritmech, jako jsou Prophet, Silverkite, Isolation Forest či statistický model SARIMA.
Velkou výhodou pokročilých modelů je jejich práce se sezónností. Při pevně nastaveném alertingu nám systém začne „šílet“, jakmile nastartuje sezóna — a to i v případě, že používáme dynamické hodnoty. Stejná situace pak nastane i po konci sezóny. Algoritmy naopak dokáží tyto výkyvy zohlednit, protože vidí souvislosti napříč historickými daty.
Pokročilé modely ale mají i svá úskalí, a to falešně pozitivní signály. Doporučujeme proto postupné nasazování, při kterém se odladí věci, které jsou sice z pohledu modelu anomálie, ale nás jako specialisty nezajímají — počítáme s nimi a nepotřebujeme, aby nám k nim chodily alerty. Rovněž je vhodné rozlišit kanály podle kritičnosti — málo prioritní záležitosti mohou být uloženy v souboru bez notifikací, ke středně důležitým přijde e-mail a u vysoce nestandardních a kritických anomálií dorazí SMS.
A poslední doporučení: nebojte se používat více algoritmů zároveň. Mohou se vzájemně kontrolovat a ověřit, zda se opravdu jedná o anomálii, ještě předtím, než se informace dostane ke koncovému uživateli.
Technologické okénko
V rámci webináře projevili někteří účastníci zájem o technologickou část alertingu, proto si níže popíšeme, jak takové workflow může vypadat.
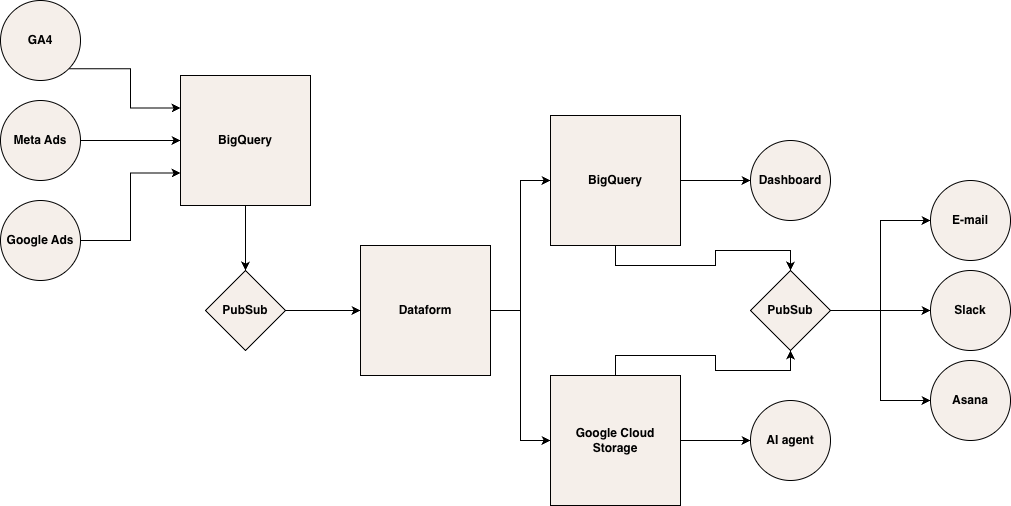
Zjednodušené schematické zobrazení možné workflow
Na vstupu potřebujeme samozřejmě data. V tomto případě budeme pracovat s daty z GA4, Google Ads a Meta Ads, která se nám skrze konektory nahrávají do BigQuery. Jakmile máme data kompletní (např. za předchozí den), Pub/Sub spustí Dataform (případně dbt), kde probíhá veškerá modelovací magie.
Zpracovaná data uložíme zpět do BigQuery, případně do Google Cloud Storage. Na BigQuery máme zpravidla napojené dashboardy, k souborům v Google Cloud Storage pak přistupuje AI agent. Jakmile jsou obě služby naplněny, Pub/Sub tuto informaci zaregistruje a odešle alerty do cílových systémů.
Pub/Sub hraje v celé workflow nezastupitelnou roli, protože orchestruje operace pouze nad kompletními daty. Teoreticky by ho šlo nahradit cron jobem, který se spustí pravidelně v 7:00, ale mohlo by se stát, že v tu dobu ještě nebudou data kompletní. A kompletní data jsou podmínkou pro to, aby datový alerting fungoval správně.
Je třeba dodat, že se jedná pouze o zjednodušený příklad. U klientů, kde řešíme AI agenty a alerting, se konkrétní podoba liší v závislosti na jejich potřebách a nástrojích. I zapojení AI agenta je možné udělat více způsoby — může přistupovat ke strukturovaným datům v GCS (jako ve schématu), data lze odesílat na klientův on-prem server nebo může agent přistupovat k datům pomocí MCP.
Důležitý je individuální přístup, což zmiňoval i Adam na webináři — jedno univerzální řešení, které by sedělo každému, neexistuje.
Jak s alertingem začít?
Popsali jsme si, co alerting je, proč bychom ho chtěli mít a v čem nám může pomoci. Jak s ním ale začít, aniž bychom ihned budovali monstrózní systém?
První, co bych doporučil, je zamyslet se nad tím, jaké informace potřebujete. Probíhá váš pracovní den tak, jak jsem popsal na začátku článku? Jaké signály vám pomáhají k tomu, abyste se rozhodli, co s kampaní udělat? Podle jakých indikátorů poznáte, zda je kampaň úspěšná? A pokud jste C-level, jaké informace a v jaké frekvenci vás zajímají? Chystá vám je nějaký zaměstnanec, který tomu věnuje jednotky či desítky hodin? Nešlo by to automatizovat?
Potřeby musí být jasně definované, ale nesmí jich být příliš mnoho. Důvod je prostý — chceme se vyvarovat false positive signálů. Pokud nám každý den chodí e-mail s potenciálně problémovými kampaněmi a my pokaždé zjistíme, že je vlastně všechno v pořádku, začneme ho časem ignorovat. Únava z alertů (alert fatigue) je hodně diskutované téma, a proto bychom jí měli předcházet. Alertovat chceme jen to, kde je opravdu problém.
Jakmile máte potřeby sepsané, máte v podstatě sadu pravidel, kterou je pak nutné implementovat do systému podobnému tomu ve schématu výše — s čímž vám velmi rádi pomůžeme.