Co znamená triangulace u vyhodnocování v marketingu? Co tvoří její součásti a proč už samotné atribuce nestačí? Adam sepsal hlavní body z prosincového tučňáčího webináře o vyhodnocování.

Donedávna bylo vyhodnocování v marketingu založené téměř výhradně na atribuci. Jednoduchý koncept, kdy se podle nějakého pravidla rozpočítává, jaký vliv měly jednotlivé kanály a kampaně na nákup.
Koncept atribucí od začátku stojí na základech, které ale nejde jednoduše naplnit. K problému s cross-device (lidé mají takový ošklivý zvyk, že stránky navštěvují z více než jednoho zařízení) se přidala zákonná a technická omezení. GDRP nám nakazuje, kdy můžeme měřit a aby toho nebylo málo, háží nám v tom klacky pod nohy i prohlížeče a zařízení. Jeden příklad za všechny představuje Apple a jeho Intelligent Tracking Prevention.
To neznamená, že by už atribuce byla úplně nepoužitelná, jen se na některé činnosti už nedá spolehlivě použít. Například na rozdělování rozpočtů.
Co se s tím dá dělat?
Bohužel neexistuje jeden nový kouzelný přístup, který by nahradil atribuci a my tak jen přešli z jednoho nástroje na jiný. Bude za tím daleko víc práce.
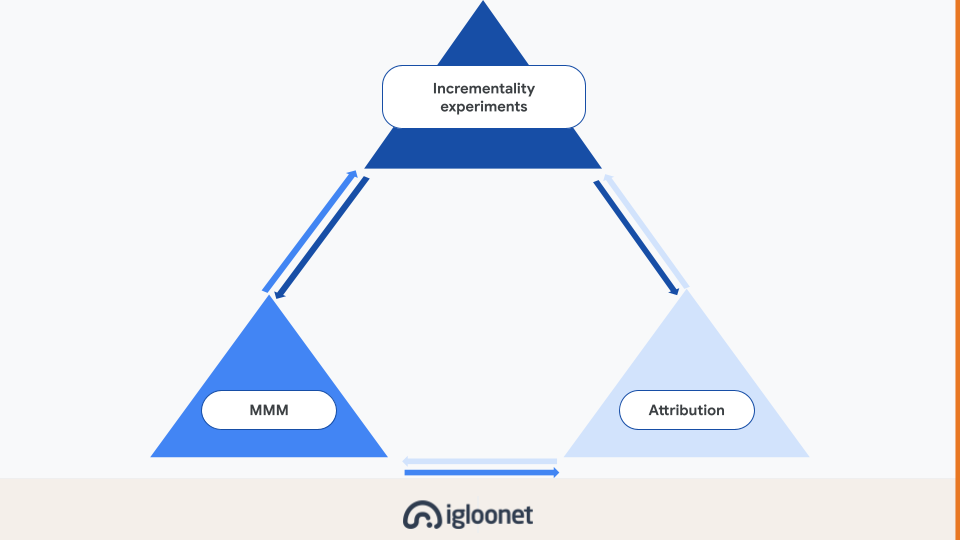
Odpovědí se zdá právě triangulace. Tedy kombinace různých metod pro vyhodnocování.
V současné době se za její části považují inkrementální experimenty, media mix modelling a stále atribuce.
Atribuce

Atribuce je založená na jednoduché myšlence: důvod, proč se zákazník rozhodl k nákupu, se skrývá v jeho nákupní cestě. A buď se jedná o jednoduchý model (typu za nákup může poslední zdroj v jeho cestě), nebo sofistikovanější “data-driven” model, který tu hodnotu dopočítává.
S atribucí pracuje každý nástroj webové analytiky a každý reklamní systém. Způsob práce se ale zásadně liší.
Pokud například vyhodnocujete kampaně v Metě, nejspíš se vám zdá, že jsou ta čísla nějak nafouklá. Že si prostě Facebook snaží přisoudit větší zásluhy, než jaké mu patří. Ten důvod je celkem jednoduchý. Meta a priori nevidí, z jakých dalších zdrojů se zákazník na web dostává. Zaznamená, že uživatel proklikl kampaň A na Facebooku a pak, že za pár dní nakoupil na stránce inzerenta. A to, že mezitím prošel přes Google, Heuréku a Sklik remarketing, už Meta neví. Pokud bychom tedy takto sčítali konverze z různých reklamních nástrojů, zákonitě bychom se dostali na větší číslo, než kolik je celkový počet nákupů v administraci.
To je právě výhoda nástrojů typu Google Analytics, Mixpanel, Roivenue. Tím, že počítají atribuci uceleně pro všechny kanály, dělají tzv. deduplikaci konverzí. Nemůže se tak stát, že by byl v GA vyšší počet konverzí, než kolik jich reálně přišlo. Teda pokud nemáte nějakou chybu v měření.
Koncept atribuce se často připodobňuje k fotbalovému zápasu. Nechceme dávat kredit za výhru jen útočníkům, kteří střílí góly, ale chceme lépe pochopit, jak se na výhře podíleli i ostatní hráči. Jen ta analogie funguje pouze za předpokladu, že vyhodnocujeme první a druhý poločas zvlášť. Bez toho, že bychom řešili jakýkoliv vztah mezi nimi. A navíc nám u toho trochu na televizi vypadává obraz, takže občas přehlédneme přihrávku. Stačí nám takový způsob vyhodnocování, abychom na tomto základě dělali rozhodnutí o změnách v týmu na další sezónu? S největší pravděpodobností ne. Ale dost možná nám stačí k tomu, abychom věděli, koho v daném poločasu odvolat a poslat na lavičku.
A u fotbalových analogií ještě chvíli zůstaneme. Vzpomeňte si na fotbal, který jsme hrávali na základce. Třída se nějak rozdělí do dvou týmů a hraje. A nyní si představte Frantu. Nedá se o něm říct, že by mu fotbal nějak šel, ale zato je dostatečně chytrý na to, aby si spočítal, který tým má větší šanci na výhru a k němu se přidal. A když na závěr školního roku budeme vyhodnocovat nejlepšího hráče čistě podle toho, kolikrát byl členem vítězného týmu, kdo myslíte, že si odnese trofej? Přesně takto se chovají některé platformy či reklamní modely. Snaží se spočítat, jaká je šance, že uživatel nakoupí tak jako tak a zobrazují mu svou reklamu, aby se do jeho nákupní cesty ještě zvládly nacpat.
Co se může zdát paradoxní, tak jednoduchý lastclick model (tedy všechny konverze náleží poslednímu známému zdroji) daleko míň rozbíjí, že nejsme schopni napárovat návštěvy mezi zařízeními a že nám občas chybí data kvůli cookies. Záleží mu totiž primárně pouze na té poslední návštěvě a co se dělo předtím, jde mimo něj.
Inkrementální experimenty
Oproti atribuci jim vůbec nezáleží na tom jak vypadá nákupní cesta, kolik je na ní touchpointů ani žádné složité rozpočítávání. Zajímá je čistě, zda by ke konverzi došlo, či nedošlo, kdybychom danou kampaň nedělali - jaký je inkrementální přírůstek dané kampaně. Což je hrozně důležitý rozdíl oproti atribuci, která automaticky rozpočítává všechny konverze. Nejen ty navíc.
Inkrementální experimenty jsou založené na causal inference a můžeme k nim přistoupit vícero způsoby. Zlatý standard jsou randomized controlled trials, tedy staré dobré AB testování. Jen to bohužel málokde u vyhodnocování kampaní můžeme využít (výjimkou je např. Meta conversion lift) a musíme přistoupit k jiným metodám, u kterých si kontrolní skupinu musíme nějak vytvořit.
Jednu z možností jak si vytvořit kontrolní skupinu využívá CausalImpact. Dejme tomu, že v říjnu děláme velkou akci, kterou chceme vyhodnotit. CausalImpact nejdřív jakoby zapomene říjnová data a predikuje, jak by říjen dopadl, kdybychom akci nedělali. Tuto predikci pak srovná s reálnými daty a odhaduje jak velký měla akce doopravdy vliv.
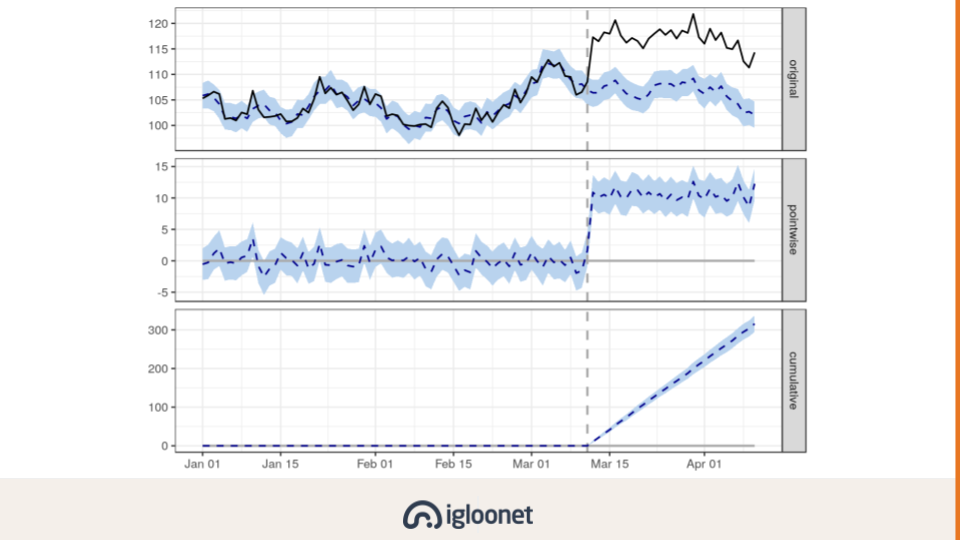
Opravdu elegantní způsob jak vyhodnotit dopad akce. Jediná nevýhoda je, že CausalImpact je založený na predikčním modelu, který měl větší aktualizaci naposledy před 6 lety a možnosti predikce se za posledních pár let celkem posunuly. Proto mi dává větší smysl využít funkcionalitu Causal Impactu a aplikovat ji na přesnějším predikčním modelu.
Jiný způsob jak vytvořit kontrolní skupinu využívá GeoLift. Ten srovnává výsledky experimentu s tzv. syntetickou kontrolní skupinou založenou na územních celcích. Vybereme stát / kraj / okres, na kterém chceme experiment provést a GeoLift nám dopočítá takovou kombinaci ostatních území, aby byly tomu původnímu před provedením experimentu co nejpodobnější.
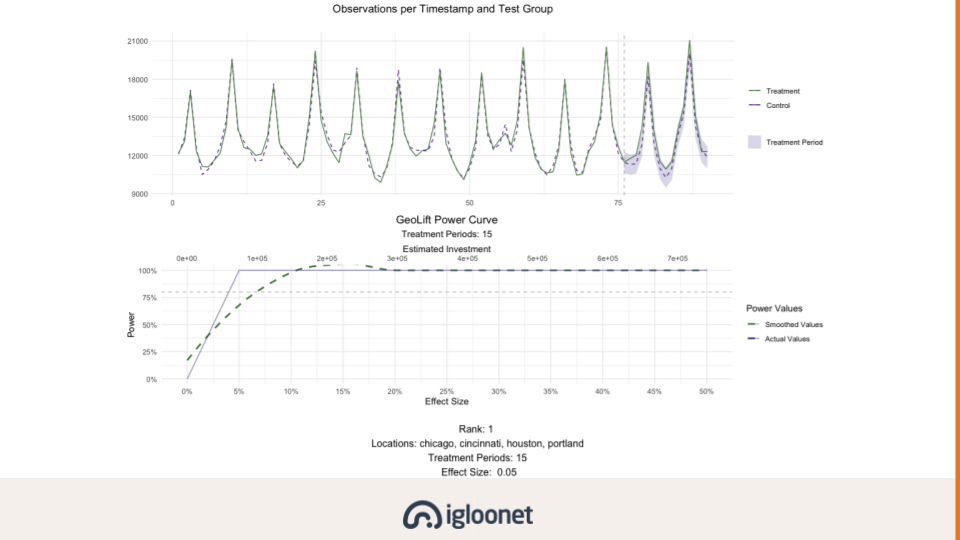
Tím se řeší například problém se silným hlavním městem. V kontrolním mixu jej použijeme třeba jen s váhou 0,1 tak, abychom chování v hlavním městě zohlednili, ale zároveň aby nám úplně nezkreslilo výsledky.
Práce s okresy a kraji je kvůli spolehlivosti cílení vždycky složitější, a proto se s ní u nás moc nepracuje. Pokud jsme ale do designu experimentu schopni dostat ten územní prvek, je interval spolehlivosti zpravidla výrazně užší než u CausalImpactu. Bude tedy přesnější v odhadu efektu.
Nejnáročnější na celém experimentu je příprava dat a zejména jeho správný design. Vždy je daleko jednodušší řešit, jak experiment vyhodnocovat předtím, než dojde ke spuštění kampaně / překopání marketingového rozpočtu než ex post. Často si tak můžete ušetřit dost práce s ohýbáním modelu, když všechno od začátku odladíte.
Media Mix Modelling
Poslední díl triangu-skládačky tvoří media mix modelling (MMM). O něm jste nejspíš slyšeli poprvé v posledních 3 letech, ale je založený na ekonometrických metodách, které tu jsou s námi už pár dekád. Není to tak žádná rychlokvaška. Jen je teď díky větší výpočetní síle daleko dostupnější i pro běžné firmy a ne jen pro těch pár největších.
Příslib MMM je opět velmi elegantní. Nepotřebujeme znát cestu zákazníka, nejsme závislí na doměření a propojení každé návštěvy. Stačí nám nějaké exposure metriky (nejčastěji se pracuje s impresemi či dosahem), útrata v rámci daného kanálu a celkové tržby. Ne tržby dle kanálů pomocí nějaké atribuce, ale opravdu celkové tržby, které v daném období byly.
A mezi těmito dvěma stranami rovnice se nachází model, který se snaží namodelovat závislosti. Jaký vliv na celkové tržby má zvýšení impresí v Google Ads o 30 %? Jaký vliv bude mít snížení rozpočtu pro Metu o 10 %?
Zní to trochu “too good to be true”. Nejsme závislí na cookies ani jiném trackování, odpadají tak problémy s přílišným zásahem do ochrany osobních údajů a stačí nám čistě ta data, která bereme z interního systému a z reklamních platforem. Navíc oproti atribuci se snaží vyčíslit baseline (co bychom měli čistě setrvačností a silou naší značky) a co navíc nám kampaně přinášejí. To přece nemůže být tak jednoduché?
Moje dvě hlavní připomínky od začátku byly: všechny marketingové aktivity mají nějaké zpoždění a míra zpoždění se navíc u jednotlivých kanálů dost liší (rychleji mi začnou přicházet tržby z kampaní ve vyhledávání než z televize, na druhou stranu ty z televize budou mít nejspíš delší “dojezd”) a kampaně není možné škálovat do nekonečna. Budou pracovat s nějakou mírou saturace, která se bude postupně zvětšovat. Nestačí mi tedy proložit na jedné straně imprese s útratou a na druhé tržby a čekat, že dostanu relevantní výsledek.
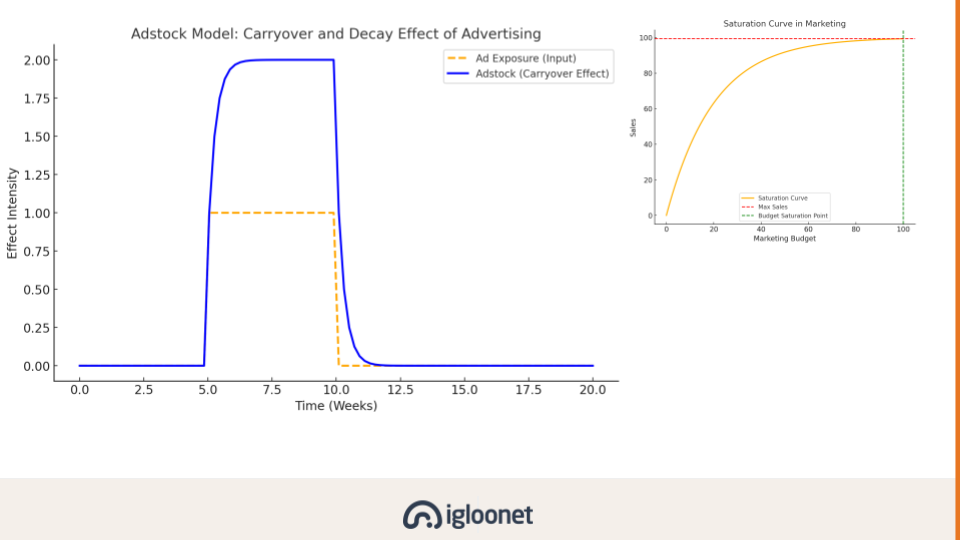
Ale i s carry-over efektem (zpoždění + setrvačnost) a mírou saturace naštěstí MMM počítá.
Jen to už dost zvyšuje složitost modelu, a tak aby mohl něco relevantního napočítat a ty závislosti trefit správně, potřebuje k tomu spoustu dat. V MMM se proto nikdy nedostaneme na takovou granularitu, s jakou pracujeme v rámci atribuce. Pracujeme s ním tedy buď na úrovni zdrojů, nebo logických kampaňových celků (např. remarketing, vyhledávání, social organic) a abychom k tomu dostali rozumná sezónní a trendová data, je naprosté minimum připravovat model na alespoň 2 letech dat. Díky tomu, že nám stačí data z reklamních platforem a interního systému,se nemusíme naštěstí zaobírat takovými detaily, jako je nekonzistence mezi Universal Analytics a GA4 daty.
MMM zní skvěle, proč ho tedy nevyužít jako náhradu atribuce? Hlavní důvod je ta nízká granularita (na úrovni kampaní nám moc nepomůže) a relativně dlouhá doba reakce na změny. Pokud nenastane opravdu velký výkyv, na denní úrovni nám MMM moc s vyhodnocováním nepomůže.
Triangulace
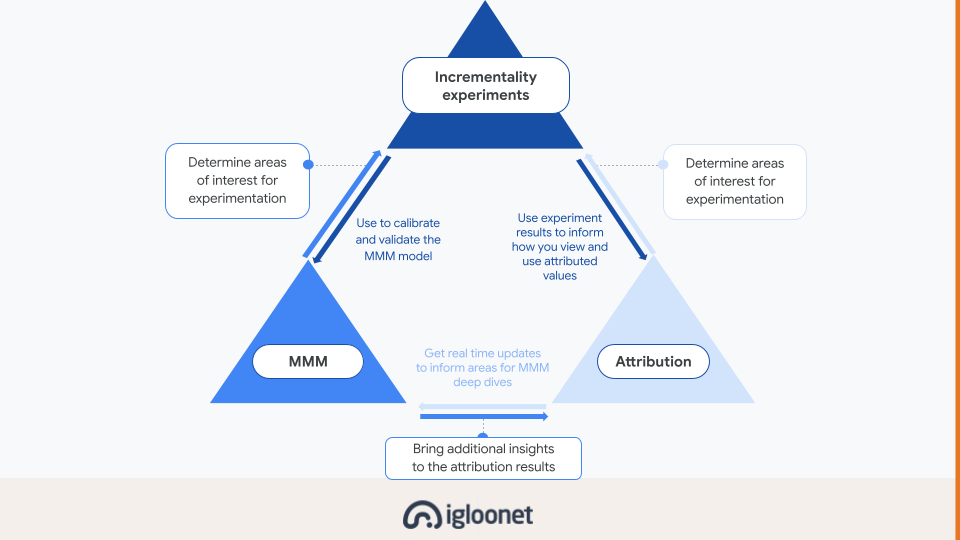
Co tedy s tím? Atribuce se nehodí pro větší změny typu rozdělování rozpočtu mezi kanály, inkrementální experiment je náročný na spuštění a vyhodnocení a MMM zase nevyužiji na běžnou optimalizaci kampaní.
Odpovědí není jeden jednoduchý přístup, který nám vyřeší všechny otázky vyhodnocování, ale umět si vždy vybrat, který přístup se nejvíc hodí pro problém, který řeším.
Potřebuji optimalizovat kampaň? Atribuce mi naprosto stačí, protože primárně řeším, jestli se zlepšila / zhoršila, či jak se jí daří oproti stejnému typu kampaní (jakmile začnu porovnávat odlišné typy a kampaně v různých fázích nákupního cyklu, užitečnost jde celkem rychle k nule).
Řeším efektivitu jednotlivých kanálů / typů kampaní a chci dosáhnout lepšího výtlaku tím, že líp přesunu rozpočet? Použiji media mix modeling.
Všechno jsou to ale modely a neměli bychom jejich doporučení brát slepě jako bernou minci. S jejich ověřením a zpřesnění do budoucna nám pomůžou inkrementální experimenty. Tvrdí mi MMM, že Meta je o 40 % podhodnocená? Spustím inkrementální experiment, zjistím, že sice podhodnocená je, ale reálně je to spíš 10-20 %. Upravím dál MMM model, aby Metu tolik nenadhodnocoval. Z toho mi pravděpodobně vypadne, že je podhodnocený jiný kanál a celý proces můžu zopakovat.
tldr
- atribuce už nestačí na větší úkoly vyhodnocování typu úpravy rozpočtů
- není jiný kouzelný nástroj, který by ji nahradil ve všech částech vyhodnocování
- proto se používá triangulace - kombinace přístupů
- atribuci stále používáme na denní optimalizaci kampaní
- MMM může zvýšit celkovou efektivitu díky lepšímu rozdělení marketingového rozpočtu
- inkrementální experimenty ověří reálný dopad kanálu / kampaně a díky nim tak můžeme zpřesňovat atribuční i media mix model
A dál?
Na webináři jsme probírali ještě alternativy k atribučnímu modelování, ale jako úvod do triangulace je to dostatečně hutné, tak si to nechám zase pro další článek.
Nechcete si nechat ujít další tučňáčí webinář? Po datové přípravě na expanzi s Martinem Anderkem z GymBeam pokračujeme Media Mix Modellingem. Přihlásit se můžete tady.