7. září se uskutečnil MeasureCamp v Praze, kde opět nesměla chybět tučňáčí delegace. Tentokrát ale ve značně osekaném složení, protože dva důležití členové, Adam a Tomáš, museli ze zdravotních důvodů zůstat doma. Aby však nepřišli o žádné důležité informace, pozorně jsme poslouchali všechny přednášky a vytvořili i detailní zápis. A jelikož by byla škoda nechat si nově nabyté poznatky pro sebe, rozhodli jsme se, že se o ně podělíme i s vámi, našimi čtenáři. Pokud se tedy chcete dozvědět, jaká zajímavá témata se probírala, tak pokračujte ve čtení!

Před čtením si můžete osvěžit paměť článkem z loňského MeasureCampu v Bratislavě, případně porovnat s pražským MC z roku 2016!
Poprvé v Praze!
Pro oba z nás to byl první MeasureCamp, kterého jsme se v Praze zúčastnili. V oblasti konferencí patříme mezi nováčky. Míša navštívila MeasureCamp úplně poprvé a Dominik byl předtím pouze v Bratislavě.

Naše přednášky na session boardu
Nekonference se konala v krásných a nových prostorách centrály ČSOB na Radlické. Program doplňovalo skvělé jídlo a káva, kterou jsme si společně s čajem mohli dát téměř kdekoli, kde jsme se zrovna nacházeli. Snadno jsme natrefili i na čtyři přednáškové místnosti, které byly centrem veškerého (vě)dění!
Náš measurecampový příspěvek!
Jako obvykle jsme si připravili vlastní přednášku a workshop. Dominik povídal o důležitosti datových vizualizací a datově-vizualizačním minimalismu. Míša oproti tomu zvolila formát diskuzního workshopu, ve kterém se zaměřila na problematiku laktózové intolerance a toho, co je možné vyčíst z dat slovenského statistického úřadu.
Přednáška o minimalismu postupně sklouzla k diskuzi, ve které se řešila mimo jiné funkce reportů a zda a jak je klienti čtou. Zajímavé bylo rovněž sledovat, jak se mezi posluchači lišil názor na to, kolik minimalismu ve vizualizacích je ještě přípustné a kdy už minimalismus škodí. Pokud byste i vy chtěli nasát tuto zajímavou přednáškovou atmosféru, koukněte se na doprovodný článek nebo prezentaci.

Dominik společně s příznivci datových vizualizací
Míšin diskuzní workshop, nebo-li mentální rozcvička, se zabýval laktózovou intolerancí a tím, zda dokážeme dojít k závěru pomocí nákupních dat. Workshop si kladl za cíl, aby se účastníci zamysleli nad tím, jaká data a datasety bychom potřebovali k vyvrácení, či potvrzení hypotézy. Míša vedla workshop v angličtině, což redukovalo počet zúčastněných. Kvalitě diskuze to však neubralo. Všichni přítomní se aktivně zapojovali do debaty, dohledávali si informace a argumentovali.

Miša v diskuzi s účastníky workshopu
Měření webview v mobilních aplikacích
V jedné z největších místností si vzal slovo Michal Nováček, který přispěl svými zkušenostmi z měření webview v mobilních aplikacích.
Webview je webová stránka, která je integrovaná přímo do prostředí samotné mobilní aplikace. Pro běžného uživatele je téměř k nerozeznání, zda se nachází v nativním prostředí mobilní aplikace, nebo zda aplikace využívá na aktuální zobrazení webview. Důvodem používání webview je cena – integrace webview je z hlediska vývoje mobilní aplikace daleko levnější než programovat danou část přímo do aplikace.
Pokud mobilní aplikace využívá webview, ulehčí sice práci vývojářům, ale přidá vrásky nám analytikům. Správná implementace měření navíc bývá problematická. Je nutné vyřešit potíže s případnými duplicitními daty, protože uživatel je změřený při používání aplikace a rovněž při příchodu na webovou stránku. Při běžném používání appky tak uživatel „pendluje“ sem a tam.

Michalova ukázka toho, co je a co není webview
Michal představil tři řešení problému s webview, přičemž všechna mají svá pozitiva i negativa.
Prvním řešením bylo odesílání všech dat do jednoho webového data streamu, přičemž při zobrazení webview by se do URL odeslal parametr, že se jedná o webview. Nevýhodou tohoto řešení je ale nutný zásah vývojářů. U mobilních aplikací totiž změny nelze implementovat tak jednoduše, jako u webu, kde stačí změny pouze publikovat v GTM.
Jako druhé řešení představil Michal měření pouze do aplikace, přičemž by bylo nutné posílat informace z webu do appky, např. URL nebo pageTitle. Opět zde ale vyvstávají problémy, a to menší míra kontroly toho, co se měří. Rovněž musíme nějakým způsobem ošetřit, aby se při webview nespouštělo GTM na webové stránce, respektive aby se neměřilo duplicitně do webového streamu.
Poslední představené řešení je dle Michala ideální. Web odesílá skrze GTM parametry do aplikace. Samotná aplikace ovšem obsahuje listenery, které jsou připravené na informace z webového GTM. Jedná se asi o nejlepší a nejelegantnější řešení, ale zároveň i složitější řešení. Vyžaduje totiž, aby vývojáři uměli psát vlastní listenery. Rovněž není zatím možné tímto způsobem posílat e-commerce data.
Z publika padla otázka na duplicitní zobrazování consentové lišty. Tento problém je jedním z největších v kontextu webview, protože se chceme vyhnout dotazům na práci s cookies a uživatelskými daty. Ideálně nechceme vůbec zobrazovat cookie lištu v prostředí mobilní aplikace. Z proběhnuvší diskuze ale vyplynulo, že řešení tohoto problému zatím nemáme nebo je poměrně komplikované na implementaci.
Jak na architekturu datového skladu
Kuba Kříž patří mezi největší odborníky z hlediska datové architektury a zpracování dat v Google Cloud Platform. To dokázal i svojí hodinovou přednáškou, na které udržel posluchače i přes přestávku. Upřímně lituji kohokoliv, kdo měl svou session v době konání Kubovy druhé session - z natřískané místnosti málokdo odešel. Není se čemu divit, protože nám dal nahlédnout do nitra práce datového architekta a na co všechno je potřeba při návrhu datových řešení myslet.
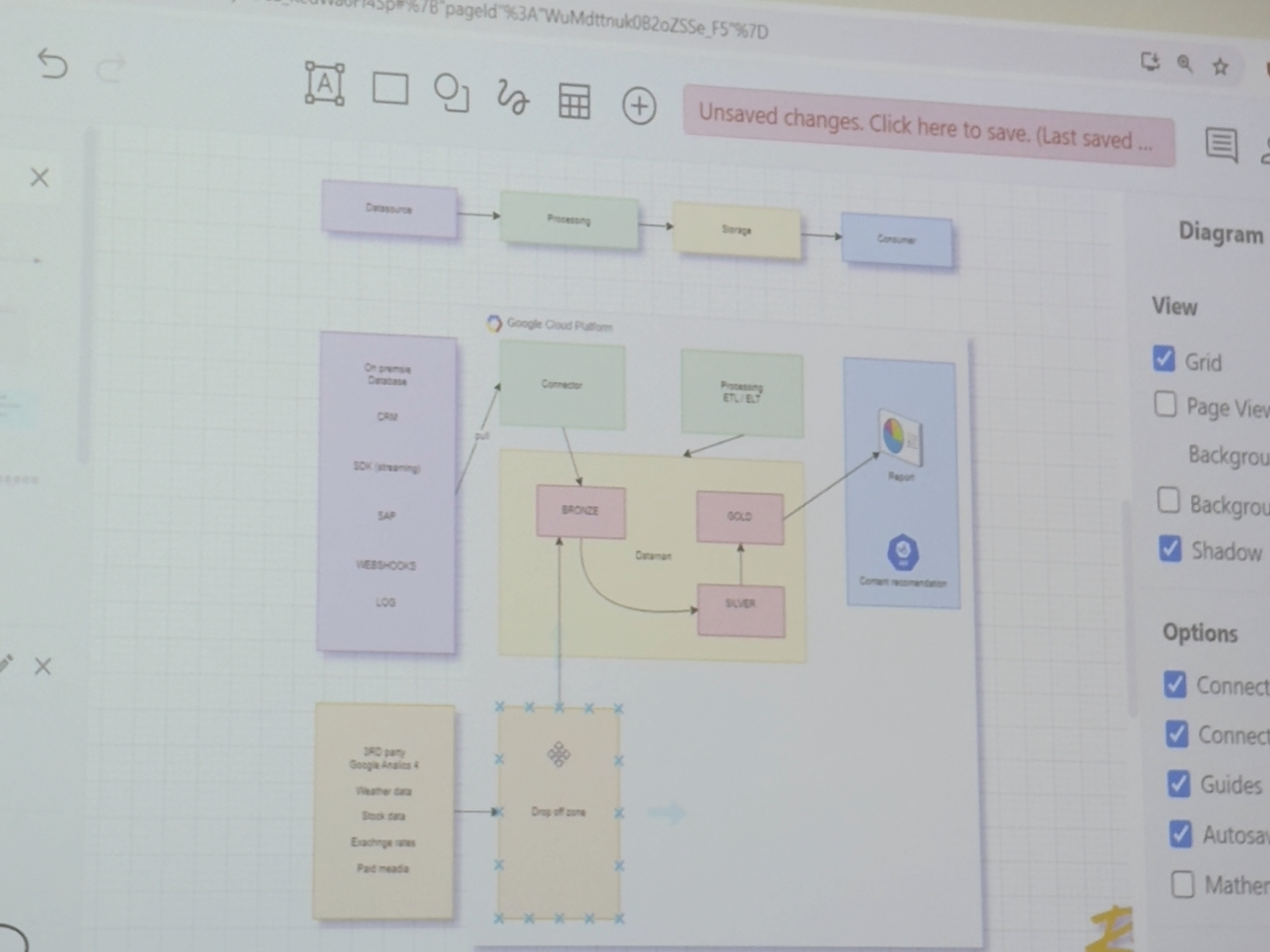
Praktická ukázka práce datového architekta
Kuba velmi často zmiňoval, že je důležité mít při plánování datových řešení vše dobře uspořádané a promyšlené, a to nejlépe od samého začátku. Hned úvodu nám proto představil první kroky při plánování. Klíčové je si vše nakreslit a správně rozvrhnout, což nám Kuba ukázal interaktivní formou, konkrétně názornou tvorbou diagramu. Oba nás velmi překvapilo, na co všechno musí datový architekt při vymýšlení různých řešení myslet. Stejně tak nás udivilo, kolik služeb vlastně Google nabízí. Na každou z nich dokonce existuje ikonka!
Přednášku bychom popsali jako velmi komplexní a prakticky zaměřenou. Největší přínos vidíme v ukázce toho, co všechno je potřeba při návrhu datových řešení mít na paměti. Nelze opomenout stakeholdery a především ty, kdo nám platí účty. Je třeba myslet i na správné datové zdroje, mít vyřešený compute power a rovněž tak úložiště dat. Vzhledem k širokému výčtu je nutné si vše vizualizovat. Pojistíme si tak, že na nic nezapomeneme.
Hlavně ať nám v GCP nic neuteče!
Marek Čech svoji přednášku, jak sám řekl, „splácal při obědové pauze“. To jí ale rozhodně neubralo na kvalitě! Za své si vzal Cloud logging a především mnohdy opomíjený alerting. Právě alerting nám přijde jako jedna z nejužitečnějších funkcí, které jsou v GCP nativně poskytnuté.
Co je na alertingu tak super? Jakmile se objeví nějaká chyba, systém upozorní vybrané uživatele na předem definovaných kanálech, že je něco špatně. Tato funkce se pak stává neocenitelnou, zvláště pokud u klientů provozujeme Dataform nebo například SGTM. Marek se především věnoval tomu, jak vše nastavit tak, aby nám už žádná chyba neunikla.
Důležité je vědět, že standardní logy se uchovávají po dobu 30 dní. Toto uložení není ale zadarmo, protože každý log obsahuje informace, které se musí někde uložit a za toto úložiště i zaplatit. Google poskytuje nějaké menší free limity, ale po jejich vyčerpání začíná být logování poměrně nákladné.
Samotné alerty můžeme jednoduše vytvářet z logů – když nastane událost, o které chceme být informovaní, tak z daného logu uděláme alert a vybereme si kanál, na který nám o dané události přijde upozornění. Nejvíce využívaný je e-mail, ale upozornění lze doručit i na telefon formou SMS nebo do kanálu ve Slacku.
Za nás je určitě potřeba dodat, že si musíme dát pozor, na co vše alerting nastavíme. Měly by to být opravdu závažné události, protože pokud se parametry nastaví příliš striktně, budou nám na e-mail chodit desítky upozornění denně. Tato upozornění přestaneme po pár dnech registrovat a začneme je cíleně ignorovat. To ale bude problém, pokud se stane něco opravdu závažného. Alerting tedy využívejte, nicméně všeho s mírou!
Privacy sandbox. Opravdu konec 3rd party cookies?
Tomáš Komárek se zhostil tématu Privacy sandboxu, které velmi úzce souvisí s koncem cookies třetích stran. Právě představení této nové funkce, která by měla končící podoporu 3rd party cookies ze strany Googlu nahradit, bylo náplní celé přednášky.
Privacy sandbox je nástrojem, který respektuje soukromí uživatelů, ale zároveň zcela neznemožňuje firmám v cílení inzerce, které je doteď realizované skrze 3rd party cookies. Vše stojí na samotném prohlížeči, ve kterém se vyhodnocují data a který rozhoduje o tom, jaká data pošle dál. Základem jsou interest groups, na které budou inzerenti cílit, přičemž o tom, zda uživatel bude nebo nebude součástí groups, rozhodne samotná technologie Privacy sandboxu nebo sám uživatel v nastavení prohlížeče.
Privacy sandbox je ale pro spoustu lidí nová věc, a to i mezi analytiky. Za tím zřejmě stojí fakt, že Google tento nástroj nikde moc nezmiňoval. Google navíc teď mění spoustu věcí, jak dokládá třeba jeho nedávné prohlášení, ve kterém částečně odpískal konec cookies třetích stran.
Celý systém funguje tak, že jednotlivé weby a uživatelé jsou klasifikovaní do již výše zmiňovaných interest groups. Na tyto interest groups cílí inzerent. Reklamní prostor se získává tzv. bidováním, přičemž se biduje právě na interest groups v samotných reklamních systémech, které přenechají reklamní prostor nejvyšší nabídce.
Technologie Privacy sandboxu má ovšem řadu problémů, přičemž některé z nich jsou inherentně dané samotnou technologií. Web, na kterém se nachází reklama, například nemůže vědět, jaká konkrétní reklama se na bannerech zobrazí. S tím souvisí i to, že publisheři ani advertiseři nevidí stejná data a v neposlední řadě ani to, že publisher nevidí, kdo vyhrál aukci.
Největším problémem nadále zůstává zpoždění v zobrazení bannerů, které je momentálně o 1500 milisekund (1,5 sekund) delší, než tomu bylo doposud. Toto zpoždění se nemusí zdát jako velké, nicméně velmi ovlivňuje zásah reklamy a v konečném důsledku i konverzní poměr. Z testování zatím vyplývá, že se snižuje sledovanost reklam o zhruba 50 %. Zpoždění způsobuje aukční systém, přičemž je možné aukce obejít. Pokud se jí však vyhneme, tak už vůbec neovlivníme, kde se bude reklama zobrazovat (respektive na jakých typech webů atd.) Tomuto systému obcházení aukce se říká passback ads.
I když je Privacy sandbox oficiálním řešení Googlu v kontextu cookies třetích stran, tak uvidíme, co nám ještě přinese. V dohledné době o něm ale budeme slýchat čím dál tím více.
Jak a proč nastavit export GAds do BigQuery
Vašek Jelen a Anička Horáková si podobně jako Kuba Kříž zabrali celou hodinu (dokonce i ve stejné místnosti). Řeč ale nebyla o datové architektuře, nýbrž o exportu dat z Google Ads do BigQuery. Obojí však spojuje stejné prostředí, a to Google Cloud Platform.
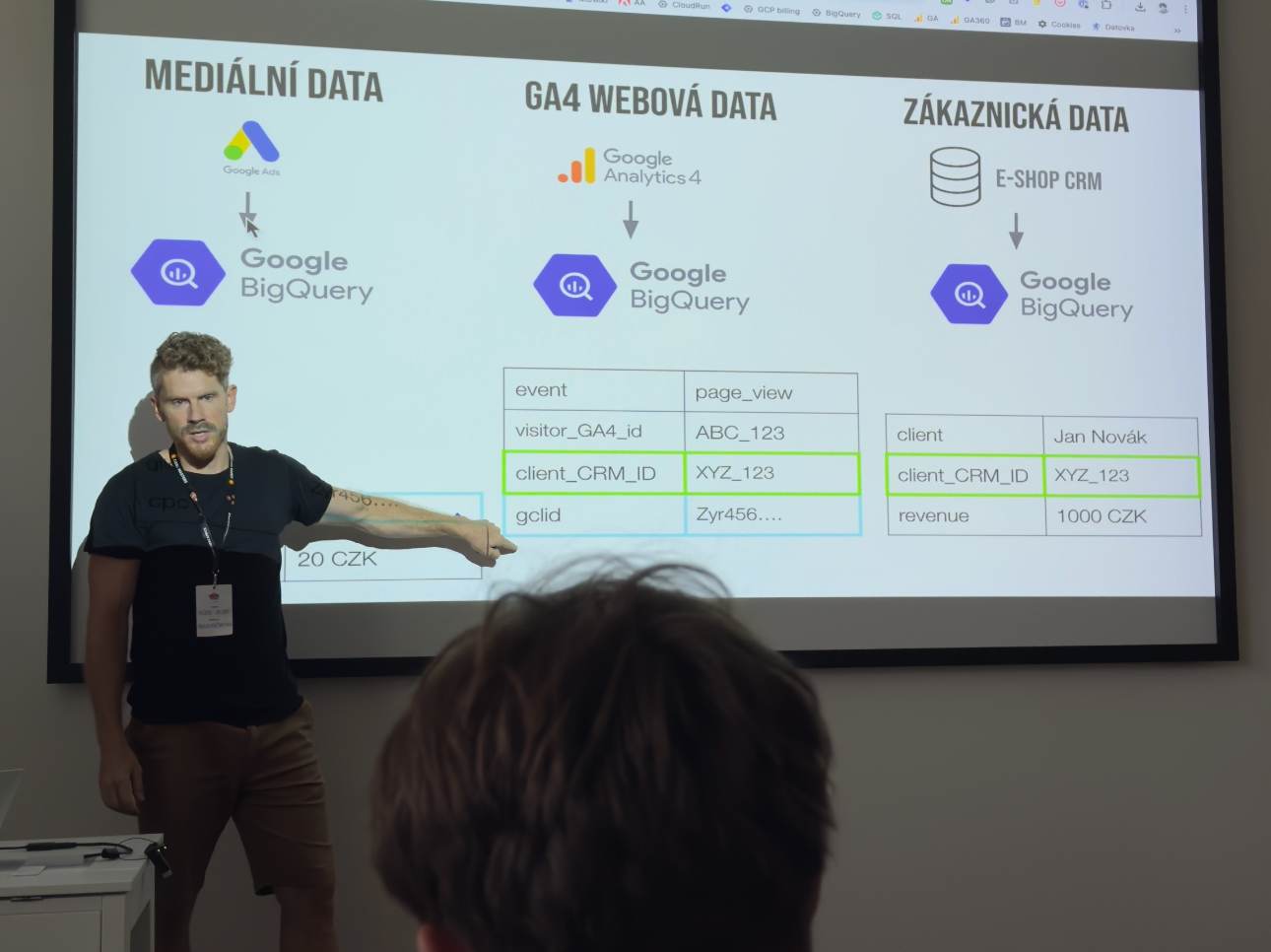
Vašek a jeho popis toho, dle čeho lze párovat uživatele
Přednášku začal Vašek teoretickou částí, ve které mluvil o důležitosti exportu a celkově i nutnosti používání BigQuery. GA4 mají totiž řadu problémů a především nám prezentují domodelovaná a agregovaná data, což nás při práci velmi svazuje. Kromě BigQuery lze použít i jiné databáze a systémy, nicméně hlavní výhoda tkví v tom, že se většinou chceme pohybovat v jednom stacku, což je ve spoustě případech Google stack.
Centralizace přináší výhody v podobě používání offline dat, které si do databáze můžeme odesílat z interního systému. Je důležité mít ale nějaký identifikátor, dle kterého uživatele spárujeme. Nejčastěji se jedná o různé typy věrnostních či klubových kartiček.
Anička navázala na Vaška praktickou ukázkou napojení Google Ads účtu do BigQuery, respektive nás provedla vytvořením data transferu. Velmi nás překvapila beta funkce, která umožnuje už v samotném transferu udělat query a vše exportovat do jedné tabulky. Tímto query ušetříme spoustu prostoru a především celý export zpřehledníme. Nyní je s GAds transferem spojený export více než sta tabulek a jejich views. Tato beta funkce bude snad dostupná všem na konci tohoto, nebo na začátku příštího roku.
Layered Intelligence aneb jak přistupovat k datům
Jednoduchost efektivitu přináší! To bylo jedno, ne-li hlavní, heslo přednášky Mirka Černého o jeho metodě přístupu k datům. Mirek se rozpovídal o oddělení jednotlivých vrstev dat, díky čemuž jim jasněji porozumíme a zároveň se vyhneme problémům. Mirkův přístup, který spočívá v rozpadu dat na jednotlivé úrovně, ve výsledku nabízí hloubkovou analýzu. Tu využijeme například k identifikaci a včasnému oslovování zákazníků. Při své práci využívá například Latency, což je medián času mezi objednávkami, a Recency, tedy kdy naposled si klientův zákazník objednával zboží.
V igloo máme s RFM analýzou bohaté zkušenosti. V tomto článku se dozvíte více o tom, jak jsme pracovali s Recency.
Mirek ve své přednášce srozumitelně popsal celý proces, který aplikuje na data a popsal i několik případů, kdy díky své analýze dokázal odhalit kritické body, spící zákazníky nebo ty, kdo potřebovali trochu popostrčit.
Mirkův rozpad analytického procesu byl podle mě skvělou ukázkou přístupu k práci s daty. Přednáška byla dle mého názoru velmi obohacující, ať už Mirkovu metodu použijete, nebo ne. Mirek nám svým výkladem dokázal přiblížit, jak hluboké porozumění každé jedné vrstvy dat umožňuje nadstavbu a potažmo hloubkovou analýzu. Lépe tak porozumíte zákazníkovi a jeho potřebám. U klienta zase snáze identifikujete příležitosti, o kterých ani on sám neví.
Prioritizace práce
Pokud si někdo myslí, že se na MeasureCampu oběvují pouze analytická témata, tak se šeredně mýlí. Tomáš se svojí kolegyní nám totiž prezentovali svůj přepracovaný návrh systému prioritizace práce. Nás a rozhodně i více lidí téma zajímalo, což se odráželo v množství otázek, návrhů a nápadů na zlepšení a v celkové debatě, která se na session strhla.
V jejich návrhu hodnocení získává každý úkol skóre z rice score model. Důležitost zadání má čtyři úrovně, tři úrovně finančního dopadu, stejné množství úrovní dopadu na zákazníka nebo zaměstnance. Pravděpodobnost dopadu je v modelu vyjádřená bodově, časové ohodnocení je rovněž zvážené a v potaz se bere i MoSCoW metoda.
Výpočet hodnocení vypadá následovně:
RICE model (level x benefit x impact x confidence) / effort
Prezentace přešla plynule k diskuzi, ze které vyvstalo několik bodů. Nejvíce času se věnovalo subjektivnímu vnímání složitosti práce nebo její časové náročnosti, kde by řešením mohlo být využití AI pro vyhodnocení RICE skóre. Dalším bodem byl návrh dvou metrik – metrika pro spolupráci s vývojem, což prodlouží trvání úkolu, a karma zadavatele, která by mohla vést k vyšší kvalitě úkolů, protože řešitelé si nemusí zadání dekódovat.
V konečném důsledku byla tato prezentace výbornou ukázkou, jak se zamyslet nad větším objemem úkolů a jak se vyvarovat situaci, že (doplňte si váš interní systém) vypadá jako vánoční stromeček na Štědrý večer.
Uvidíme se už za necelý měsíc v Bratislavě!
MeasureCamp v Praze závěrem hodnotíme velmi pozitivně. Vyslechli jsme spoustu zajímavých přednášek, díky kterým můžeme zlepšovat služby pro naše klienty. A také jsme se po dlouhé době viděli se spoustou našich kolegů z oboru. Kromě nezávazného pokecu či vyprávnění vtipných historek jsme si vyměnili i cenné zkušenosti – v tom v podstatě celá akce spočívá
Chcete se pobavit i s námi? Tak dorazte 19. října na bratislavský MeasureCamp. My tam určitě budeme!