Customer Lifetime Value, neboli CLV či LTV (Lifetime value) není jen metrika, ale způsob uvažování o zákaznické hodnotě, který prostupuje celou firmou. Podrobněji jej v našem Tučňáčím webináři rozebírali Adam s Markem. Mluvili o něm jako o nástroji, který pomáhá firmám porozumět hodnotě zákaznické báze a řídit byznys z hlediska dlouhodobé udržitelnosti. CLV poskytuje rámec pro pochopení, jak různé segmenty zákazníků přispívají k růstu firmy. Zároveň umožňuje lépe alokovat rozpočty, plánovat produktový vývoj nebo optimalizovat retenční strategie.

CLV umožňuje vnímat zákazníka nikoli jako jednorázovou transakci, ale jako dlouhodobý ekonomický vztah s významným dopadem na celkový chod firmy. Nejde jen o to zjistit, kolik zákazník již utratil, ale především odhadnout, jakou hodnotu může přinést v budoucnu. Tento posun od čistě historického pohledu k predikci budoucího vývoje představuje klíčový prvek moderního řízení zákaznické báze. CLV tak firmám umožňuje přemýšlet nad segmentací, akvizičními strategiemi i retenčními aktivitami s větší jistotou a s dlouhodobou perspektivou. I proto se tato metrika stává zásadním rozhodovacím nástrojem pro CEO, CFO či marketingové ředitele.
Proč by mělo CLV zajímat vedení firmy
CLV nám přináší mnoho praktických poznatků. Pomáhá snadno zjistit, kde se vyplatí investovat, kteří zákazníci budou s největší pravděpodobností profitabilní a kde je potřeba přehodnotit strategii - například kvůli neudržitelnému nárůstu akvizičních nákladů nebo nízké kvalitě nových zákazníků. Mnohá klíčová rozhodnutí se stále zakládají na intuici, ale CLV nabízí přístup, který dokáže intuici nahradit a rozhodování tak zpřesnit. Jako vždy jsou to právě data, která dávají vedení firem informace o stavu marketingových aktivit a výhledech do budoucna. Díky nim si mohou klást správné otázky a efektivně se rozhodovat:
- Jak se liší zákazníci z různých zdrojů?
- Ve kterých segmentech má smysl navyšovat péči a rozpočet? Kde je naopak na místě opatrnost nebo přehodnocení stávající strategie?
- Jaká je hodnota naší zákaznické báze?
- Jaká je optimální cena za akvizici nového zákazníka? Nerozhodujeme se náhodou podle jednorázového profitu?
- Nerosteme náhodou na dluh a nepadáme tak do slevové pasti?
CLV zde působí jako kompas, který pomáhá zorientovat se v různorodých datech a přeměnit je na konkrétní akce. V tomto kontextu tak není CLV jen číslo, ale důležitý nástroj pro strategické řízení růstu. Vytváří most mezi analytikou a exekutivou a přináší jazyk, kterému rozumějí jak datoví specialisté, tak vedení firmy.
Na webináři nám Adam prozradil, že CLV nejraději využívá pro identifikaci slevové pasti. Firmy zpravidla pořádají slevové akce, aby si krátkodobě zvýšily tržby. CLV jim pak ukáže, zda ten samý zákazník, který by stejně nakoupil, si díky slevové akci neudělal objednávku dříve a levněji. Pokud se po takových akcích hodnota CLV nezvyšuje, kampaň zcela jistě nepřinesla požadovaný efekt.
Marek na webináři zmiňoval příklad s mobilní aplikaci – zákazníci v appce jsou zpravidla hodnotnější než zákazníci na webu. Co se ale stane, když lidi z webu nalákáme ke stažení aplikace? Zvýší se jejich hodnota, když si aplikaci stáhnou? Nebo zůstane stejná, protože mají pořád jednu a tu samou peněženku? Nevíme, proto je potřeba to zjistit výpočtem CLV.
Adam následně uvedl další dva netradiční příklady konkrétního použití. První se týkal Amazonu, který využívá CLV ve svém dynamic pricingu. Zákazníkům s nejvyšším CLV personalizovaně nabízí jejich nejčastěji nakupované produkty za nižší ceny a zbytek za ceny normální či mírně zvýšené. Tyto kroky mu umožňuje dělat výpočet CLV, díky kterému si Amazon segmentuje ty nejhodnotnější zákazníky, za něž je ochotný i více utratit. Druhým příkladem využití je řízení skladu – máme produkty, které se sice tolik neprodávají, ale jelikož je kupují naši nejhodnotnější zákazníci, tak je naskladníme přednostně. Rozhodně totiž nechceme, aby tito zákazníci nakoupili jinde a my o ně přišli.
Jak se CLV počítá a proč je lepší začít jednoduše
Na webináři zaznělo, že CLV není jedním konkrétním číslem nebo jediným výpočtem, ale spíše škálou přístupů, které se liší svou složitostí, datovými požadavky a interpretovatelností. Je proto zásadní vybrat takový přístup, který odpovídá jak vyspělosti firmy, tak dostupnosti dat.
Než s nápočtem začneme…
Heuristika a ARPU
Některé firmy začínají s výpočtem na základě průměrné hodnoty objednávky a frekvence nákupů, nebo dokonce jen jako „součet tržeb do dneška“. Tento přístup je jednoduchý, ale značně omezený – reálně se jedná spíše o ARPU (Average Revenue Per User) než o skutečné CLV. I přesto může být užitečný pro prvotní segmentaci a ověření, jak velké rozdíly v hodnotě zákazníků mohou ve firmě existovat.
Segmentace (např. RFM)
Před jakýmkoli výpočtem CLV se často používá segmentace – například RFM (Recency, Frequency, Monetary), která poskytuje základní vhled do chování zákazníků. I bez pokročilého modelu může RFM pomoci řídit marketing, retenci a prioritizaci péče.
Možnosti výpočtu CLV
Probabilistické modely (BG/NBD, Pareto/NBD)
Tyto modely vycházejí z principů RFM a díky své jednoduchosti byly v e-commerce historicky jedny z nejpoužívanějších. Modelují, s jakou pravděpodobností zůstane zákazník aktivní, a odhadují počet nákupů, které ještě uskuteční. Často se kombinují s Gama distribucí pro odhad hodnoty objednávky. Tyto modely jsou vhodné pro PoC (proof of concept) a poskytují solidní predikci i při omezených datech.
Model má ale i své nevýhody – např. předpokládá, že frekvence objednávek a jejich hodnota jsou na sobě nezávislé. To je ale velmi problematické, protože se často stává, že vyšší frekvence objednávek s nižší hodnotou (nebo naopak) neumožní zachytit problémy s poklesem CLV při slevových akcích.
💡Diskontování - budoucí zisky lze diskontovat na současnou hodnotu pomocí úrokové míry. Tento přístup se však podle zkušeností z praxe používá minimálně – je příliš akademický a málo praktický.
Markovovy řetězce
Tipsport experimentoval také s Markovovými modely, které počítají přechody mezi segmenty zákazníků. Tento přístup ale není příliš rozšířený – v praxi u něj nezůstali.
Regresní modely a strojové učení
Pro firmy s větším množstvím dat jsou ideální regresní modely – například stochastický gradient boosting (LightGBM). Tyto modely přímo predikují budoucí zisk a dokáží pracovat s desítkami vstupních proměnných (kanál, produkt, demografie, chování). Jsou přesnější, ale náročnější na interpretaci. Tento přístup aktuálně využívá Tipsport.
AutoML
Cloudové nástroje jako AutoML (např. Google Cloud) umožňují rychle otestovat predikční modely CLV bez velké investice do vývoje. Výhodou je rychlost, nevýhodou black-box charakter a potenciální problémy s ochranou dat.
Hybridní přístupy
Firmy mohou kombinovat probabilistické modely s ML algoritmy – například predikovat nákupní frekvenci pomocí BG/NBD a hodnotu nákupů pomocí regrese. Tyto přístupy jsou nejkomplexnější a vyžadují pokročilé analytické dovednosti.
Kratší predikční horizonty
U kratších predikčních horizonů většinou z praktického hlediska nedává smysl pracovat s čistým CLV. U většiny firem se napočítává hodnota zákazníka pro další rok / dva. V gamingu je toto období extrémně zkrácené na 7⁄30 dní.
💡CLV podle podobných zákazníků – vyhodnocovat CLV lze i na základěpodobnosti zákazníků. Na to se používá buď vlastní model, nebo je součásti ML modelů, které nepracují jen s objednávkovým profilem zákazníka, ale i s jeho chováním.
To ale může do CLV modelu přinést větší míru nahodilosti, a proto doporučujeme ho využívat buď u opravdu velkých zákaznických dat, nebo v případě, kdy není k dispozici mnoho dimenzí. Např. u gamingu je tento přístup jednodušší, jelikož hlavní rozdíly v chování mají pár metrik (jak dlouho člověk hraje, co ve hře dělá). U e-commerce firmy je však chování a CLV zákazníka dost odlišné a závislé na nakoupené kategorii / produktu, čímž mohou být podobnostní data dost řídká.
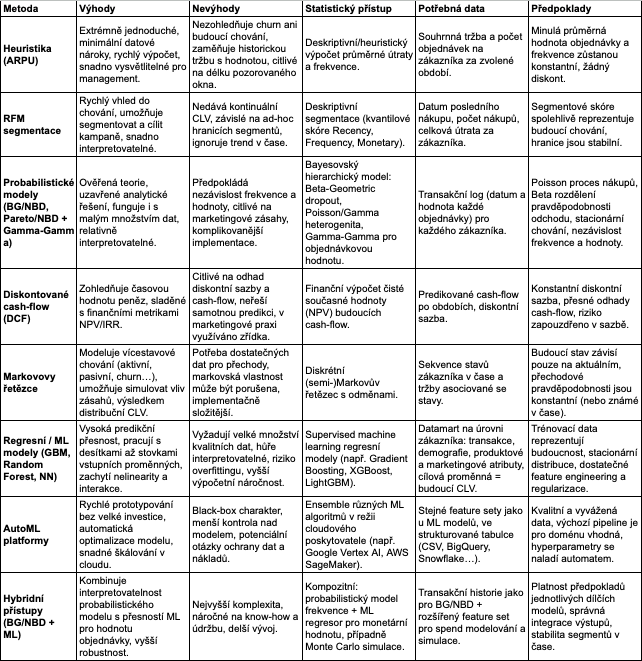
Přehledné srovnání jednotlivých přístupů k CLV
Bez segmentace se téměř neobejdeme
Segmentace je v kontextu CLV považována za jeden z klíčových předpokladů, bez kterého nemá smysl s výpočtem vůbec začínat. Na webináři zaznělo, že firmy by měly mít zvládnutou základní datovou přípravu – například segmentaci pomocí RFM (Recency, Frequency, Monetary) – dříve, než se pustí do modelování CLV. RFM poskytuje jednoduchý, ale silný rámec pro pochopení zákaznického chování a umožňuje i bez pokročilých modelů zodpovědně řídit marketing i komunikaci.
Výpočet CLV pak velmi často probíhá na úrovni segmentů. Například skupina zákazníků, která v poslední době často nakupovala a utrácela vyšší částky, se liší od skupiny, která nakoupila naposledy před rokem, a i jejich odhadovaná hodnota je jiná. Ve zkratce bývá výpočet CLV na úrovni segmentů jednodušší, lépe škálovatelný a často i přesnější než pokusy o granularitu na individuální úrovni – zejména v případech, kdy jsou data řídká nebo obsahují velké množství šumu.
V začátcích se doporučuje soustředit se na „větší shluky“ zákazníků a přiřazovat hodnotu celým skupinám. V praxi to může znamenat rozdělení zákazníků podle zdroje akvizice (např. organický vs. placený kanál), typu první objednávky (např. sportovní kategorie), nebo zařízení (web vs. app). Firmy tak mohou snadno porovnávat, které segmenty přinášejí vyšší CLV a podle toho řídit alokaci rozpočtů nebo cílení kampaní.
CLV a segmentace jdou zkrátka ruku v ruce. Hodnota zákazníka získaného přes aplikaci může být jiná než u zákazníka ze slevové kampaně, a právě segmentace tento rozdíl zvýrazní. Pokud například jeden segment zákazníků reaguje výrazně lépe na retenční program nebo má delší životní cyklus, má smysl s ním pracovat jinak než s méně výnosnými skupinami. V Tipsportu například dělali segmentaci podle zájmu o konkrétní sport, protože zákazníci s různými sportovními preferencemi můžou (ale nemusí) mít odlišnou hodnotu.
Zároveň platí, že u některých typů firem je lepší počítat CLV na individuální úrovni. Například „outlier“ skupiny, což jsou zákazníci s extrémním chováním nebo ti, kteří využívají výhradně bonusové akce, mohou zkreslit průměry celého segmentu. V takovém případě je vhodné vytvořit oddělený model nebo přístup. Cílem je vždy zvolit správnou rovnováhu mezi komplexitou modelu a obchodní použitelností výsledků.
V neposlední řadě je třeba zmínit tzv. value-based segmentaci – tedy skupiny zákazníků rozdělené podle jejich ekonomického přínosu. Pokud firma spočítá CLV na úrovni jednotlivců, může tuto hodnotu následně použít jako základ pro tvorbu segmentů a řízení priorit napříč obchodem i marketingem. Tento přístup umožňuje kombinovat sílu prediktivní analýzy s přehledností a jednoduchostí klasické segmentace.

Marek s Adamem v zapálené diskuzi o nejlepších přístupech k CLV
Limity a pro koho zkrátka CLV není
CLV je užitečný nástroj pro predikci a strategické řízení, ale pouze tehdy, pokud se používá v kontextu a s plným vědomím svých limitů. Na webináři i v doprovodné diskuzi zaznělo několik důležitých upozornění na to, kdy CLV pomáhá a kdy může být naopak zavádějící.
V prvé řadě je potřeba si uvědomit, že CLV představuje pouze odhad a ne 100% pravdu. Tento přístup vychází z historického chování a předpokladů o budoucnosti. Přesnost predikce výrazně klesá s rostoucím časovým horizontem. Zatímco krátkodobá predikce na 30 dní až rok může být relativně spolehlivá, „lifetime“ horizont několika let je vždy zatížen nejistotou. Ověřit správnost modelu na takto dlouhém období je v praxi téměř nemožné. Zároveň platí, že kvalitní predikce vyžaduje kvalitní a konzistentní data. Pokud firma pracuje s řídkými, nekvalitními nebo nekonzistentními daty, výstupy budou nepřesné. V takovém případě doporučujeme soustředit se na segmentaci a heuristické přístupy, než spoléhat na detailní modely.
CLV zároveň nedává smysl u všech typů byznysů. Například ve firmách s velmi nízkou nákupní frekvencí nebo u zákazníků, kteří přicházejí jen jednorázově – u Tipsportu je to případ voleb nebo výjimečných sportovních událostí. Není zkrátka co predikovat. Podobně tomu je u byznysů s nízkou retencí nebo u zákazníků s jedním nákupem ročně - zde nemá smysl počítat celoživotní hodnotu. V těchto případech spíše využijete přístup postavený na segmentaci nebo jednoduchých pravidlech. I ten ale může být mnohdy zavádějící, protože průměr nákupů bude nízký, ale rozdíly mezi akvizičními kanály, nebo mezi nakupovanými kategoriemi mohou být dostatečně výrazné, aby CLV mělo smysl řešit.
Problém nastává také tehdy, pokud firma nemá zvládnutou základní analytiku – například segmentaci pomocí RFM – nebo pokud jí chybí jasný use case, proč CLV počítá. Výsledkem může být analytický výstup, který nikdo nevyužije. To se týká i situací, kdy se CLV počítá příliš brzy, třeba hned po prvním nákupu – tehdy modely nejsou stabilní a výsledky bývají zavádějící. To mohou částečně vyřešit ML modely, pokud jim společně s e-commerce daty posíláme i behaviorální a demografické metriky.
V rychle rostoucích firmách, kde se akviziční mix rychle mění, mohou modely naučené na historických datech selhávat, protože noví zákazníci se chovají jinak než ti z minulosti.
Limitace nespočívají pouze v typu byznysu, ale i v použité metodě. Výpočet CLV jako prostý součet dosavadních tržeb nereflektuje budoucnost a je spíše ARPU než skutečný CLV. Výpočty na úrovni segmentů mohou být zavádějící, pokud je segment příliš malý nebo v něm jeden „extrémní“ zákazník zkresluje průměr. Probabilistické modely jako BG/NBD nebo Pareto/NBD předpokládají nezávislost mezi frekvencí a výší objednávky, což v praxi často neplatí. Navíc kvůli tomuto špatně zachycují dopady slev.
Složitější modely jsou zase náročné na interpretaci. Je těžké vysvětlit, proč model přidělil určitému zákazníkovi konkrétní hodnotu, a právě tato nečitelnost může být v interní komunikaci velkou překážkou. AutoML bývá navíc vnímáno jako „black box“, jehož výstup je sice rychlý, ale nepřehledný. Podobná komplikace nastává i při vyhodnocování dopadů kampaní bez A/B testování: bez kontrolní skupiny nelze určit, jestli růst CLV skutečně způsobila kampaň, nebo jen přirozený vývoj. A pokud do modelu zahrnujeme i náklady, například na incentivy nebo reaktivaci, dramaticky tím zvyšujeme složitost i riziko chybné interpretace.
Z těchto důvodů je klíčové přistupovat k CLV jako k užitečnému rámci, nikoliv jako k univerzálnímu a jedinému pravdivému KPI. Jeho přínos roste s datovou vyspělostí firmy, jasně definovaným účelem a realistickým očekáváním ohledně přesnosti i použitelnosti.
Co si z toho odnést?
CLV není jen o výpočtu, ale především o schopnosti myslet strategicky. Pokud přemýšlíte, jak ho využít při rozhodování o prioritách, investicích nebo segmentaci, rádi se s vámi podělíme o zkušenosti z různých projektů. Každý byznys je jiný – ale cesta od dat ke smysluplnému rozhodování má často společné prvky.