MeasureCamp Bratislava 2016
Vyrazili jsme na bratislavský MeasureCamp v rekordním počtu pěti tučňáků, aby vám nic důležitého neuniklo. Zpět do Brna jsme s sebou přivezli fůru užitečných informací. Ať už řešíte zákaznickou analytiku, sociální sítě nebo hledáte ideální datový plán, vrhněte se na náš report!
Adam, nejostřílenější z nás, rozproudil debatu na téma přípravy datového plánu pro klienta. Z centra dění to sledoval Michal a sepsal pro vás několik postřehů. Lukáše nejvíce okouzlil výzkum Martina Boroše o interakcích mezi uživateli Facebooku aplikovaný na téma slovenského referenda o tradiční rodině. Ale začněme pěkně popořádku.
Jaký by to byl MeasureCamp bez vděčné Customer Lifetime Value (CLV). Téma, které v Blavě jednoznačně dominovalo a stále nedá spát většině datových analytiků, si vzala na mušku Ivča a rozhodně to neměla jednoduché. Přečtěte si, jak se vypořádala s komprimací velkého množství informací ohledně měření CLV při minimální ztrátovosti důležitých dat.
1. Ivča: Jak na CLV?
CLV byla tentokrát probírána celkem široce. Postarali se o to zejména Marek Kobulský s ukázkou výpočtu pomocí Pareto/NBD modelu a následně Pavel Jašek s diskuzí nad tím, kde CLV použít a jaké nám může přinést benefity. Díky zákaznické analytice můžeme identifikovat nevýkonné marketingové kanály, oslovovat ty správné zákazníky a neutrácet tam, kde to není třeba. Přečtěte si, co si o CLV myslí Avinash Kaushik.
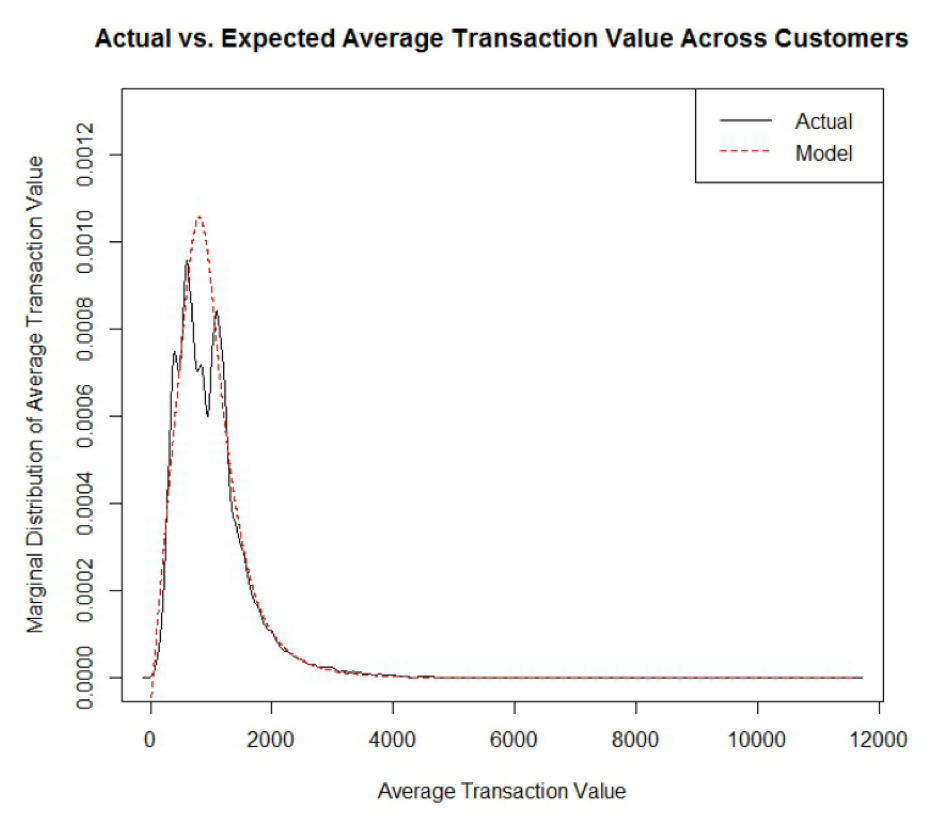
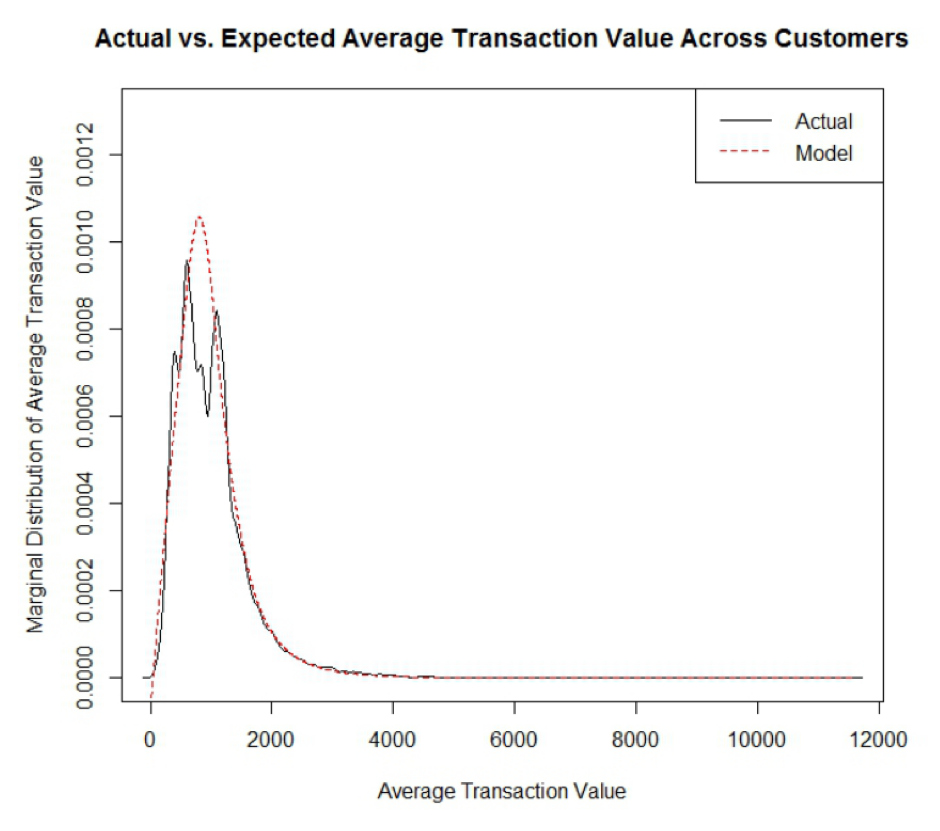
Obecně bych ráda zmínila, že 80 % účastníků Markovy prezentace odcházelo s hlavou plnou vzorců, parametrů a funkcí. Zbylých 20 % mělo alespoň minimální tušení, kolik potu Marka tato práce stála a že výsledek stojí za to. Marek se zabýval jedním z Buy Till You Die modelů (BTYD), který i přes rok vzniku (1987) překračuje svojí algoritmickou náročností něco, co se dá spočítat na běžném stolním počítači. Záleží na počtu zákazníků a zahrnutém období.
V R si můžete stáhnout package BTYD, který zahrnuje mimo Pareto/NBD i další modely. Pareto/NBD model používá Paretova pravidla, že 80 % tržeb pochází pouze od 20 % zákazníků. Nevýhodou modelu je především to, že ignoruje odpadlíky: zákazník je náš až do konce nekonečna. Jeden z výsledků CLV výpočtu je vidět na obrázku.
{kind=link}
{kind=link}
Následoval Pavel Jašek s prezentací o využití CLV v praxi. Na začátku upozornil na to, že CLV bychom neměli počítat bez jasné předchozí hypotézy. Vždy bychom měli nejdříve stanovit, co očekáváme za benefity pro svůj byznys, až potom definovat výpočet. Obvykle to však bývá naopak.
Pavel pro výpočty CLV doporučil určit období vyházející z povahy byznysu a z pravděpodobnosti opakovaného nákupu (od čtvrtetí do tří let). V průběhu prezentace proběhla diskuze o tom, že v modelu chybí náklady a CLV se stává hodnotou založenou čistě na bázi výnosů. Zajímavé by bylo porovnat model s jiným, který náklady bere v potaz.
Mezi hlavní oblasti využitelnosti CLV spadá dle Pavla akvizice nových zákazníků, jejich expanze, zákaznická podpora, udržení stávajících zákazníků, práce s přímými kampaněmi a customer intelligence. Správnou segmentací určíme výkon jednotlivých kanálů a můžeme upravit jejich nastavení. Díky tomu si odpovíme například na tyto otázky:
- Který zákazník by měl dostat slevu? V jaké výši?
- Kolik můžeme utratit za udržení stávajícího zákazníka a neprodělat kalhoty?
- Jak zacházet se zákazníky s vysokým a nízkým CLV?
- Které produkty produkují vysoké CLV?
2. Lukáš: Sociální mlhovina
S dalším zajímavým příspěvkem, a asi jediným zabývajícím se konkrétněji sociálními sítěmi, přišel doktorand sociologie na Masarykově univerzitě Martin Boroš. Ve své analýze se zaměřil na aktivitu a interakce mezi uživateli Facebooku v tématu slovenského referenda o tradiční rodině z roku 2015.
Pracoval s daty (sesbíranými mezi listopadem 2014 a únorem 2015) z největších skupin jednotlivých stran sporu, tedy skupin podporovatelů a oponentů v tématu tradiční rodiny. Za použití likes, shares a comments vizualizoval pomocí softwaru Gephi vazby (a nebylo jich málo, konečná databáze jich čítala na 79 tisíc) těchto uživatelů nebo stránek. A výsledek vidíte na schématu níže.
Oblast vlevo ukazuje hustou síť vztahů podporovatelů referenda, oblast vpravo naopak oponentů. Zásadním zjištěním je, že komunikace a interakce probíhaly zejména uvnitř těchto skupin, nikoliv mezi nimi. Šlo tedy o dva relativně samostatné světy. Přesto však mezi nimi určité vazby existují. Jsou zprostředkovány konkrétními uživateli, z nichž některé bychom mohli označit za influencery. Cíle by proto mohla podobná analýza splňovat také v oblasti e-commerce.
Pro přesnost dodáváme, že barevné odlišení propojuje segmenty uživatelů soustředěných okolo jednotlivých stránek Facebooku, konkrétního příspěvku, skupiny příspěvků či podle podobného chování. Zajímavé je, že segmenty vytvořil sám program, aniž by znal jejich obsah. I bez něj tedy dávaly smysl.
Téma rozšiřuje například výzkum Damona Centoly z University of Pennsylvania, který se zaměřil na šíření znalostí v populaci. Jeho závěry poukazují na to, že pokud je skupina příliš rozptýlená, je velmi složité pojmout jednotlivé ideje, naopak jsou-li skupiny příliš specificky oddělené, je téměř nemožné, aby se ideje vůbec šířily. Stav mezi těmito extrémy, k němuž může patřit i výzkum slovenského referenda, byl naopak „nejvodivější“.
3. Michal: Jak na datový plán?
Náš Adam se ve své session ptal, jakým způsobem vytvořit základní datový/měřící plán pro weby svých klientů. Žádný jednoduchý návod neexistuje, nicméně z krátké diskuze vyplynulo několik důležitých bodů.
{kind=link}
Několikrát byla zmíněna nutnost zapojení klienta do samotného procesu tvorby datového plánu. Sednout si a do detailu probrat, jaké jsou opravdové cíle byznysu, jaké je klientovo očekávání a jaká data k rozhodování potřebuje. Na první pohled zjevný, ale v praxi často opomíjený postup obzvlášť u marketingových agentur, pro které je důležité především měření kampaní, ale na širší kontext už tolik nemyslí.
Zazněl také zajímavý postřeh, že pro workflow během přípravy datového plánu je důležité soustředit se primárně na úkoly s vysokou prioritou a smířit se s tím, že něco se udělá později a něco možná vůbec. Pokud vás zajímá, jakým způsobem řeší měřící model špička v oboru Avinash Kaushik, elegantní a přehledný návod můžete nalézt na jeho blogu.
Ve zkratce se dá jeho návod shrnout do pěti základních kroků.
- Identifikujte základní cíle byznysu, zapojte majitele či vysoké manažery
- Identifikujte dílčí cíle
- Sepište si všechny KPI
- Pro všechny KPI si stanovte očekávané cíle
- Identifikujte jednotlivé segmenty pro analýzu
Výsledkem bude základní měřící model, který může mít například tuto podobu.
Během dne zaznělo několik přednášek, které se týkaly Google Tag Manageru. Největší porce se dočkali ti, kteří strávili skoro dvě hodiny ve smršti rad a tipů v podání André Hellera z Medio Interactive. S klidným srdcem můžu doporučit školení, které na toto téma pořádá.
P.S.: O víkendu proběhl starý dobrý MeasureCamp London a my jsme si jej opět nenechali ujít. Těšte se brzy na další dávku analytických informací.