Marketing Mix Modeling - co to je, jak s tím pracovat a na co si dát pozor
The good, the bad and the ugly marketing mix modelingu. V čem je skvělý, v jakých případech se nehodí a na co je potřeba si dát pozor. Adam sepsal hlavní body z březnového tučňáčího webináře o vyhodnocování pohledem MMM.
Vyhodnocovat efektivitu kampaní je čím dál těžší. Klacky do zákaznické cesty nám totiž hází nejen zákonná omezení (cookie / consent lišty), ale i ta technická (prohlížeče a jejich práce nejen s cookies).
A právě proto vypadá Marketing Mix Modelingu (MMM) jako ideální řešení. A tedy ideální téma pro náš poslední tučňáčí webinář.
MMM je nezávislé na cookies, “privacy-friendly”, nevadí mu, že lidé používají víc než jedno zařízení k dokončení nákupu. Můžeme pomocí něj vyhodnocovat jak online, tak offline aktivity a dokonce umí dopočítat i “baseline”. Tedy jak velkou část tržeb byste měli i kdybyste všechny marketingové aktivity ukončili.
Všechny proměnné, které pro úspěšný model potřebujete, už teď máte, nebo je můžete jednoduše získat. Ať už se jedná o metriky na straně marketingového nástroje (exposure, tedy imprese, GPRy, apod., případně reach a frekvence společně s náklady na média) nebo vaše interní data (celkové tržby, celkový počet leadů, obecně KPIs).
Model poté hledá vztahy mezi exposure / nákladovou stranou a těmito KPIs. Vztahy se navíc snaží hledat chytře. Bere totiž v úvahu základní marketingovou teorii.
Model automaticky počítá s tím, že kanály a lidé, kteří s nimi interagují, se chovají různě. Že člověk, který vidí remarketingový banner na Facebooku na nové tenisky, je nejspíš nakoupí dříve než člověk, který se s nimi setká poprvé v prerollu na YouTube. A že veškeré naše aktivity nemůžeme škálovat do nekonečna, protože postupně začneme narážet na zákon klesajícího užitku.
MMM se snaží do určité míry oba tyto body řešit:
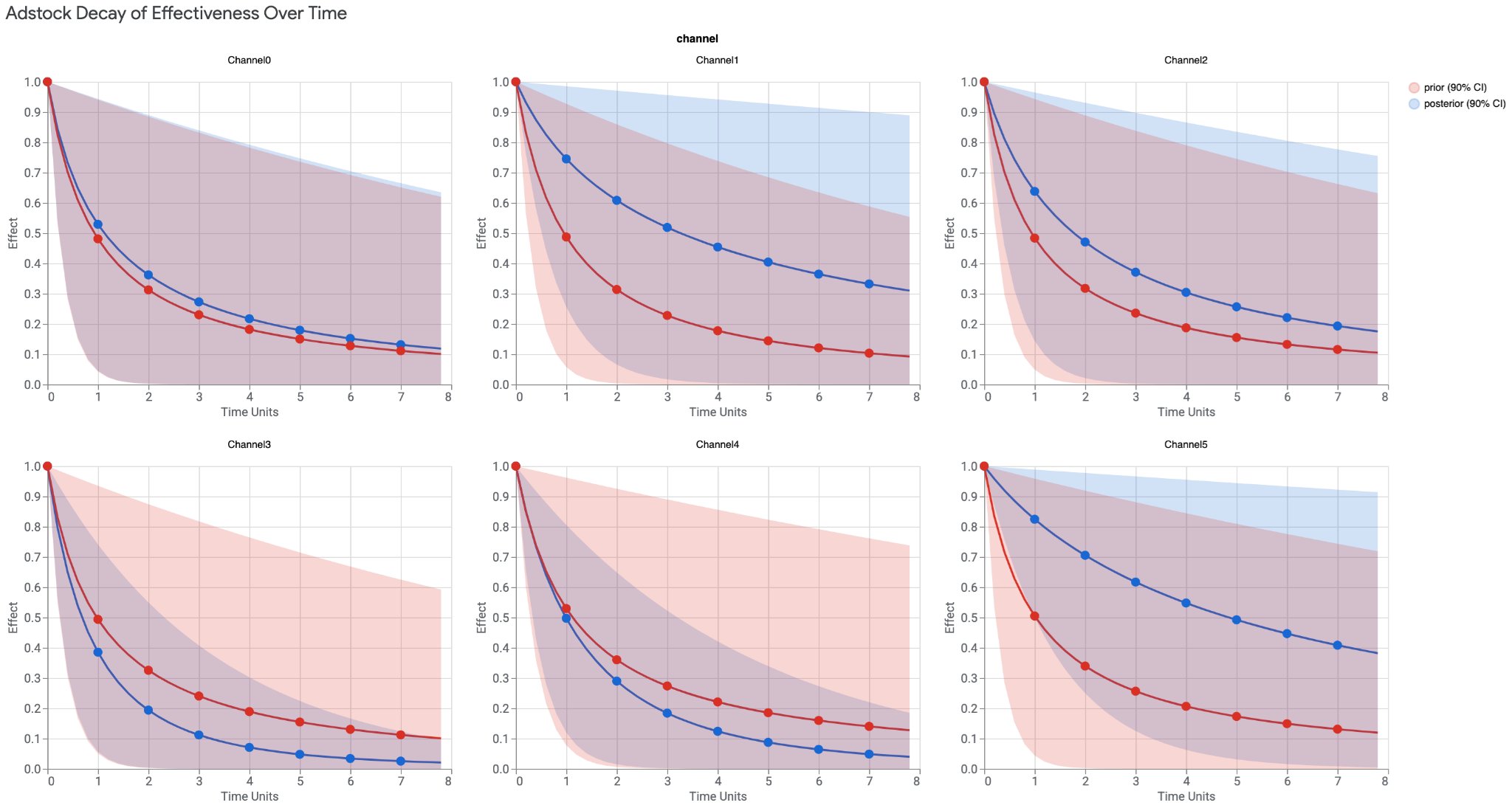
- Adstock decay- spíš než zpoždění propagačních aktivit řeší efekt slábnutí jejich vlivu v čase, ale i zpoždění se dá částečně nasimulovat;
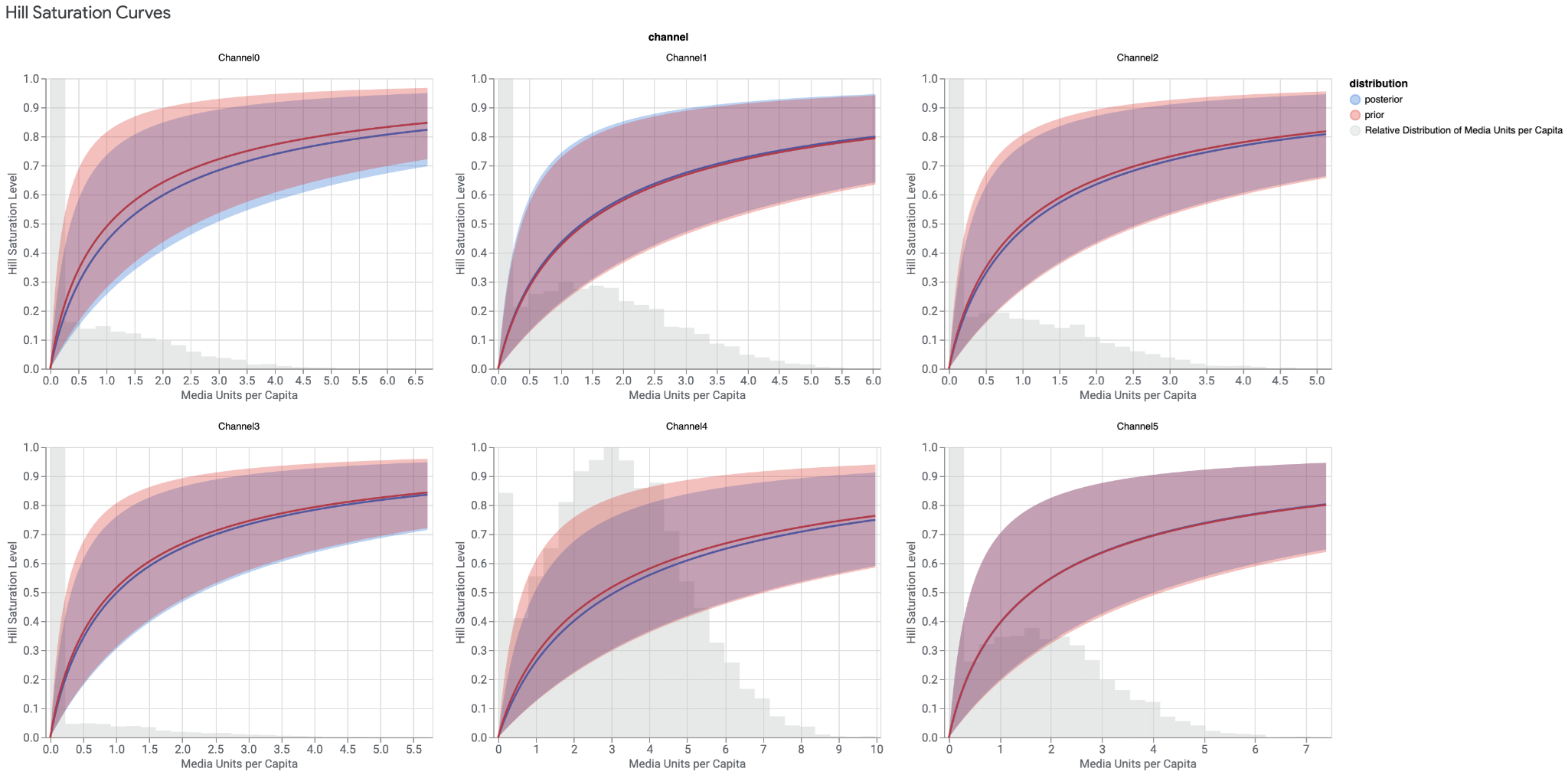
- Saturace - jaký efekt má každá další investovaná koruna a kdy, respektive jak rychle, začne efekt slábnout až do bodu, kdy každá další investovaná koruna už nemá žádný efekt.
{kind=link}
{kind=link}
{kind=link}
The good - kdy MMM použít
V současné době nemáme jinou alternativu, pomocí které bychom byli schopní dopočítat vliv vícero kanálů na celkové tržby.
Pokud tedy chceme rozhodovat o přesunu rozpočtů mezi kanály na základě dat tak, abychom dosáhli krátkodobě či střednědobě maximální efektivity, MMM je pro nás ta nejlepší volba. V dlouhodobém horizontu už tak skvěle fungovat nemusí, ale tam stejně žádný lepší model, který bychom mohli použít, nemáme. Dále jsme pak odkázání na marketingovou teorii a sledování proxy metrik.
{kind=link}
{kind=link}
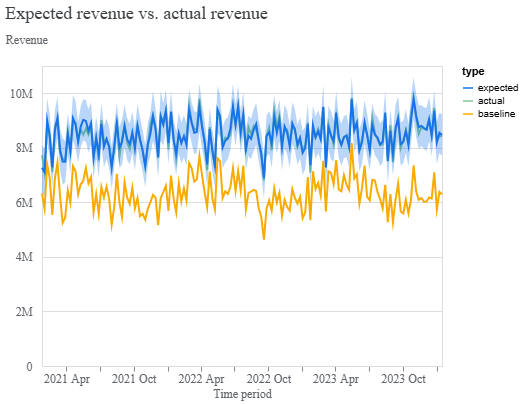
Na druhou stranu tím, že MMM nám ukazuje nejen efekt jednotlivých marketingových aktivit, ale i baseline, bývá práce s ním pro marketingové týmy často velmi náročná. Pokud totiž žijeme ve světě, kdy rozpočítáváme 100 % tržeb pomocí libovolné atribuce, výsledky MMM nás nejspíš překvapí. Zjistíme, že 75 % těch tržeb je ve skutečnosti baseline a veškeré naše marketingové aktivity ovlivňují pouze těch zbývajících 25 %. Přirozená reakce může být masivní omezení všech kampaní, což je z hlediska zdraví firmy málokdy dobrý tah. Těch inkrementálních 25 % totiž tvoří primárně noví zákazníci, kteří vám do budoucna budou baseline dál a dál navyšovat. Ideální je tedy spojit pohled skrz MMM optikou dlouhodobé hodnoty zákazníka. Ať již přes CLV, nebo jeho alternativu, tak abyste si okamžitý dopad kampaní dál zpřesnili.
Pokud tedy umíte, nebo se s baseline naučíte pracovat, je to jeden z hlavních důvodů, proč MMM používat.
{kind=link}
The bad - kdy nedává MMM smysl použít
Marketing mix modeling není nástroj na řízení kampaní na denní úrovni. Tím jak model funguje, je vhodné s ním pracovat spíš na měsíční, maximálně týdenní úrovni na větší přesouvání rozpočtů. K řízení day to day kampaní se proto nehodí. Data nezískáte dostatečně rychle a nikdy se nedostanete na úroveň jednotlivých kampaní, nedej bože reklamních sestav.
Stejně tak nedává smysl MMM použít, pokud chcete otestovat nový marketingový kanál. V tomto případě je raději zvolte nějakou variantu inkrementálního experimentu. MMM si s touto úlohou sice taky nějak poradí, ale u nového kanálu nebude mít dostatečný počet datových bodů (hodnot) na to, aby byl výsledek odpovídající.
Pokud chcete používat MMM pro svůj hlavní účel (přesouvání marketingových rozpočtů), je potřeba si nejdříve zkontrolovat, jak jsou na tom vaše současné marketingové náklady. Pokud se reklamní budgety dlouhodobě moc nemění nebo se mění na základě jiného vlivu (například sezóna), je téměř jisté, že vám model sice nějaké rozložení vytvoří, ale bude dost odtržené od reality. Dopad těchto kanálů model v podstatě zprůměruje. Kanál, který má ve skutečnosti velmi špatné výsledky, tak bude najednou vycházet celkem dobře a naopak. Hezky to ukazuje Jonathan Hershaff, data scientist z AirBnB. Čím rozházenější a “messy” marketingová data máte (náhodné vypínání marketingových kanálů, výrazné změny v rozpočtech apod.), tím lépe pro model. Čím více držíte rozdělení typu “do Skliku dáváme třetinu toho, co do Google Ads a do Mety dáváme polovinu”, tím víc budete mít práce s postupnou kalibrací. Stejně tak pokud máte “kampaně, které spouštíme jen v sezóně” - ty totiž budou v modelu vycházet v podstatě vždy extrémně nadhodnocené.
Na problém s korelací mezi jednotlivými částmi modelu narazíme i u vyhodnocování affiliate, remarketingu, či inzerování na vlastní brand.
{kind=link}
The ugly - nedostatky, kalibrace a validace
Může se zdát, že se bavíme o třech dostatečně odlišných tématech, ale všechna jsou trochu bolestivá, tak je projdeme ve společné sekci.
Doteď jsme se bavili čistě o modelaci propagačních aktivit. Ta pravá síla MMM ale přichází v momentě, kdy do něj zapojíme i další marketingové proměnné - slevové akce, větší změny v distribuci (např. otevření nové pobočky) nebo třeba rozšíření produktové řady. A to je chvíle, kdy firmy často ztratí soudnost. Co kdybychom totiž kromě marketingových kanálů zapojili nejen naše propagační akce, ale i akce konkurence, počasí a vývoj ekonomiky? Čím více proměnných přidáváme, tím více potřebujeme datových bodů. Tedy buď delší časové období, nebo jinou zásadní segmentaci - geografické rozdělení. To ale z technických důvodů většinou zvládneme rozdělit až na úrovni zemí a srovnávat data ze zemí v rozdílné dospělosti trhu a naší pozice na něm taky není úplně dobrý nápad (tam je většinou výrazně lepší mít vlastní model pro každou zemi / skupinu zemí podle jejich podobnosti zvlášť).
Takže to vyřešíme tím, že prodloužíme období, kterým model “nakrmíme”? Teoreticky správná odpověď, která naráží na jeden zásadní problém. Podmínky se v čase bohužel mění. Pár let zpátky jsme tu například měli covid. A asi málokdo bude tvrdit, že kampaně fungovaly stejně během něj i po něm. Incentivy jinak fungují v různých fázích dospělosti trhu i naší známosti na něm. A bohužel i ty marketingové kanály, či samotné kampaně se dost proměňují. To jak fungují Google Ads dnes, je diametrálně odlišné od toho, jak fungovaly pár let zpátky. Pokud se budeme tvářit, že jsou to jen drobné nuance, model sám nás na tento problém neupozorní. Proloží si data napříč časovým obdobím, dopočítá jednotlivé vlivy a vše bude vypadat na první pohled v pořádku. Jen ty výstupy bohužel nebudou příliš odpovídat realitě. Ideálně tedy začínat s rozumně dlouhým časovým obdobím (1,5 roku - 2 roky), pouze s mediálními kanály doplněnými maximálně o 1-2 další proměnné a postupně přidávat.
Třetí zábavný problém představuje tzv. mediator vs confounding variable problem. Confounding variable je proměnná, která má vliv jak na jinou proměnnou, tak na výsledek. Například objem vyhledávání je výborná confounding variable pro vyhledávací kampaně, protože zpřesňuje, jaký je dopad vyhledávacích kampaní na celkové tržby. Tedy jak moc jsme schopni ovlivnit výsledky těchto kampaní tím, že u nich budeme zvyšovat rozpočty bez toho, aniž by se zvyšovala poptávka. Mediator variable je proměnná, která je sama ovlivněna jinou proměnnou. Například objem vyhledávání je výborná mediator variable pro jakékoliv kampaně, které zvyšují poptávku (představte si třeba televizní kampaně). Takže na jednu stranu bychom chtěli využít objem vyhledávání k zpřesnění dopadu vyhledávacích kampaní, na druhou stranu vyhledávání ovlivňují přímo kampaně, které zvyšují poptávku. A jelikož v jednom modelu nemůže jedna proměnná zastávat obě role, musíme se rozmyslet, jestli je pro nás důležitější dobře vyhodnotit vyhledávací kampaně, nebo kampaně zvyšující poptávku. Existují triky, kterými můžeme jeden marketing mix model rozdělit na vícero a v každém přistupovat k objemu vyhledávání jiným způsobem, ale toto patří mezi jeden z těch případů, u kterého by mělo svítit jasné “DO NOT TRY THIS AT HOME!”.
Postupně se dostáváme k samotné validaci modelu. Jak poznat, že nám model dává opravdu relevantní výstupy? Ideálně začněme ověřením, jestli model dokáže odhalit dopad kanálů v případě, že my tento dopad známe. Jak to můžeme udělat? Vygenerujeme si dummy data, u kterých známe rozložení a dopad na tržby, nakrmíme jimi model a čekáme, jak dobře je trefí. Pokud se mu to moc nedaří, nejspíš jsme model nevytvořili úplně správně. V druhé fázi validujeme model pomocí tzv. holdout testů. Necháme model zapomenout část dat a na nich testujeme výstupy modelu. Ideálně děláme více holdout testů více v různých časových úsecích, abychom si ověřili případné zkreslení sezónností / jiným externím faktorem. Validačních technik je více, ale tyto považuji za dvě hlavní a jen jejich zapojením budete dál než většina firem, která zkouší MMM implementovat.
{kind=link}
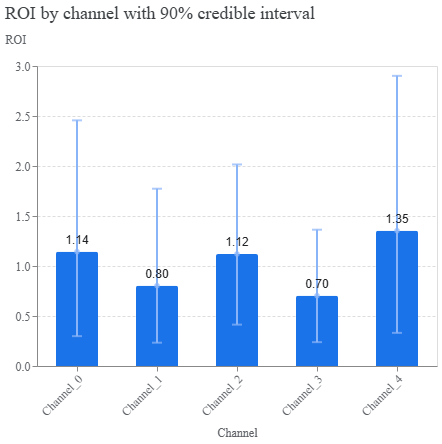
Pokud berete vyhodnocování kampaní opravdu vážně, nejspíš jste už udělali alespoň pár inkrementálních experimentů, při kterých jste vyhodnocovali dopad kampaně / marketingového kanálu. A v momentě, kdy máte první MMM výstupy, je dobré srovnat tyto výsledky s MMM výstupy. Liší se? Jak moc? Čím větší je rozdíl mezi inkrementálním experimentem a výstupem, tím větší je šance, že model není dobře postavený. Sice se můžete uchlácholit tím, že model podle výsledků inkrementálního experimentu kalibrujete (ohnete), ale je to opravdu nejlepší způsob? Neříká nám v tu chvíli model celkem jasně, že opravdový ROI není schopen odhalit a nejspíš obsahuje zásadní chybu ve svém nastavení, kterou byste měli prvně odhalit?
Je tedy kalibrace vždycky špatný nápad, který jen způsobí přepočítání ostatních proměnných, ale bez jistoty, že výstupy opravdu zpřesní? Že jen nedojde ke zkřivení na jiných místech? To bohužel nejsou otázky, na které by byly jednoduché odpovědi. Meridian je založený na bayesovském přístupu ke statistice a s potřebou kalibrací tak počítá. Jen se jedná o netriviální rozhodnutí, které může celý model rozhodit. Proto se vždy zamyslete, jestli není možné výstupy modelu zpřesnit jiným způsobem.
Zvlášť kritický jsem ke kalibraci modelu na základě case studies a literatury. Pokud si nejsme 100% jisti, jak v daném případě k výstupům přišli, není podle mě dobrý nápad je slepě přejímat a zanášet tak do modelu další potenciální zkreslení.
Možná jste po přečtení článku ztratili veškeré iluze o MMM a berete ho za slepou cestu. Ale to by podle mě byla velká chyba. Marketing mix modeling má spoustu svých problémů a specifik, které je potřeba vzít v úvahu, ale to pouze znamená, že nestačí spustit náhodný model (ať už open source, nebo postavené SaaS řešení) a máte vystaráno. Nejvíc práce zabere samotná kontrola vašich dat a validace modelu.
Nehledě na všechny nedostatky jsem stále přesvědčený, že správně vyladěné MMM je v dnešní době nejlepší nástroj na celkové řízení marketingových investic.
Co nás čeká na dalších tučňáčích webinářích
Další webinář zatím nemáme vypsaný, ale další dvě marketingově-datová témata už máme připravená. Chcete být první, kdo se o nich dozví? Zapište se.