BigQuery dnes patří mezi nejdůležitější nástroje v digitální analytice. Umožňuje efektivně zpracovávat velké objemy dat, shromáždit je na jednom místě, sjednotit a pracovat s nimi bez ohledu na to, odkud pocházejí. Jak dat přibývá a jejich kvalita často klesá, roste potřeba spolehlivého a flexibilního datového skladu. BigQuery navíc těží z úzké integrace s dalšími službami Googlu. Snadno k němu připojíte data z Google Analytics 4, Google Ads, Search Console či Google Play. Možnosti tím ale nekončí. BigQuery není omezené jen na oficiální konektory. Data do něj lze dostat mnoha různými způsoby a stejně tak existuje řada cest, jak je z něj opět vyexportovat. Tento článek se zaměřuje právě na první část: praktické metody, jak data do BigQuery načítat, a to od nejjednodušších až po ty, které využijete ve větších a komplexnějších datových ekosystémech.

Proč mít data v BigQuery
BigQuery je v digitální analytice přirozenou volbou zejména díky práci s daty z GA4. Díky nativní integraci dokáže přijímat event-level stream, tedy mnohem detailnější data, než jaká vidíme v rozhraní GA4. Místo agregovaných metrik získáme kompletní historii jednotlivých událostí, včetně parametrů, které UI vůbec nezobrazuje. Rozhraní GA4 je vhodné pro rychlé přehledy, ale pracuje s předzpracovanými daty, mění definice metrik a má limity, které ztěžují hlubší analýzu. Pokud potřebujeme přesnou rekonstrukci uživatelských cest, audit měření, kontrolu atribučních modelů nebo vlastní logiku výpočtů, BigQuery nám umožňuje pracovat bez podobných omezení.
Další zásadní výhodou jednotného datového skladu je prostý fakt, že data máme na jednom místě. Zní to banálně, ale s rostoucím počtem datových zdrojů je to kritický faktor. Ukážeme si to na běžné situaci.
Představme si e-shop, který používá GA4, několik reklamních systémů (Google Ads, Facebook, Sklik, Bing, Pinterest) a interní systém pro objednávky a účetnictví. Bez datového skladu jsou tato data rozptýlená v samostatných platformách. To komplikuje jejich porovnání, zpomaluje debugging a prakticky znemožňuje konzistentní reporting napříč zdroji.
Ano, některé věci lze propojit přímo v Looker Studiu. GA4 i Google Ads připojíme bez problémů. U dalších platforem jsme ale závislí na externích konektorech nebo skriptech, které posílají data do Google Sheets. Interní data do vizualizačního nástroje často nedostaneme vůbec, případně jen s velkým úsilím.
Takový workflow má několik slabin:
- je drahý – konektory stojí peníze a často účtují podle objemu dat, uživatelů nebo reklamních účtů,
- je roztříštěný – každý zdroj je napojen jinak a chová se jinak,
- nenabízí robustní transformace – většinu úprav buď neprovedeme, nebo je „lepíme“ přímo v Lookeru, což vytváří prostor pro chyby.
Jakmile nesedí čísla, začíná zdlouhavé hledání problému. Kontrolujeme vizualizace, transformace v Looker Studiu, chování konektorů, API limity i samotná zdrojová data, která jsou navíc roztroušená v různých systémech. A právě tento chaos řeší centralizace do BigQuery.
Nezanedbatelnou výhodou je i to, že BigQuery je součástí širšího ekosystému Google Cloud Platform. Díky tomu můžeme při práci s daty využít celou řadu dalších služeb, které na sebe přirozeně navazují. Ať už potřebujeme data získávat, transformovat, plánovat pipeline, vytvářet reporty, hlídat jejich kvalitu nebo nad nimi stavět modely či automatizace, GCP nabízí nástroje, které s BigQuery fungují bez zbytečných překážek.
Co lze do BigQuery nahrát
BigQuery dokáže pracovat s téměř jakýmkoli typem dat, a proto v něm můžeme centralizovat většinu toho, co se v běžném marketingovém nebo e-commerce ekosystému vyskytuje. Už jsme zmiňovali GA4, které jsou jedním z hlavních důvodů, proč BigQuery používáme, ale možnosti sahají mnohem dál. Do BigQuery můžeme nahrát data nejen z celé řady Google služeb, ale i z externích platforem. U některých systémů je integrace jednoduchá, u jiných složitější a záleží na tom, jak vypadá jejich API (nebo jestli API vůbec mají) nebo jaký přístup nám poskytne klient. Ve většině případů jde buď o propojení dvou databází (např. interní databáze a BigQuery), nebo o stahování dat vystavených přes API.
BigQuery však nemusíme používat jen pro „živé“ datové zdroje. Do jednoho místa můžeme konsolidovat i pomocná data, například měnové kurzy, a také historické datové sady, které byly dosud uložené třeba v Google Sheets. Tím pádem nezačínáme v BigQuery na prázdno. Naopak si do něj můžeme přenést prakticky celou historii, pokud je dostupná. To využijeme zejména u systémů, kde je stažení starších dat omezené nebo úplně nemožné.
V souvislosti s historickými daty je důležité zmínit napojení GA4 do BigQuery. Velmi často se na to zapomíná a následky jsou bohužel nevratné. Historická data z GA4 do BigQuery zpětně nedostanete. Export začíná fungovat až od okamžiku, kdy integraci zapnete, a od té chvíle se také vytvářejí denní tabulky s event-level daty. Pokud tedy plánujete pracovat s podrobnější historií, je nejlepší napojení provést co nejdříve. Samotná integrace zabere jen několik minut a ve většině případů je i cenově zanedbatelná (často neplatíte nic). BigQuery načítání dat z GA4 neúčtuje do jednoho milionu eventů denně a náklady na uložená data začnou být znatelné až tehdy, když v něm máte opravdu velké objemy. Podobně je to s historickými daty i u Google Search Console.
Z čeho naopak můžeme data dostat i zpětně, jsou vlastní databáze (u nich záleží především na životnosti dat na klientově straně). Historická data získáme i z reklamních systémů. Situace je zde sice velmi individuální, ale zpravidla lze pracovat i s daty několik let zpětně. Musíme ale počítat, že transfer zabere více času (např. 300 dní zpětně u GAds se přenáší cca týden). V případě Facebooku nás může limitovat získání produktových dat, která sice získáme historicky, ale pouze skrze vytváření a stahování reportů, což velmi zatěžuje API a tudíž je nutné provádět tento transfer velmi pomalu.
Jak dostat data do BigQuery
Teď už víme, proč BigQuery používáme a jak široké spektrum dat do něj můžeme uložit. Zbývá ještě poslední krok - jak tam ta data dostat? Možností je mnoho, ale začneme těmi nejjednoduššími, které lze nastavit přímo v jednotlivých nástrojích bez jakéhokoli kódu.
První na řadě jsou už zmiňované GA4. Integrace probíhá přímo v rozhraní nástroje a její nastavení zabere jen několik minut. Jediné, co potřebujete, je existující projekt v GCP a aktivní billing. Bez něj se vám budou data po 60 dnech automaticky mazat, a to nejen z GA4 exportu, ale ze všech datasetů uložených v BigQuery.
Na stejném principu funguje i propojení s Google Search Console. Také zde se data posílají přímo z nástroje do BigQuery a export se spustí až od chvíle, kdy integraci zapnete. Odměnou jsou ale podstatně detailnější a analytičtější data, než jaká máte k dispozici přímo v rozhraní GSC, zejména při práci s dotazy a URL.
💡Pro fungující přenos ze Search Console potřebujete mít založený service account v GCP s právy BigQuery Job User a BigQuery Data Editor.
Nativní Data transfers
U Google služeb ještě zůstaneme a podíváme se na možnost, která je při práci s BigQuery mimořádně užitečná: nativní Data Transfers. Jde o integrační nástroj přímo v GCP, který umožňuje automaticky přenášet data z vybraných služeb do BigQuery bez nutnosti psát vlastní kód. Právě zde se začíná naplno projevovat výhoda toho, že BigQuery tvoří součást širšího cloudového ekosystému.
Mezi nejčastější napojení patří Google Ads a samotná integrace je velmi jednoduchá. V prostředí GCP zvolíme Data Transfer, zadáme Customer ID a následně se automaticky spustí denní export dat. Výsledkem je rozsáhlá sada tabulek (obvykle kolem 120), se kterou můžeme dále pracovat, transformovat ji nebo propojovat s dalšími zdroji. Google nedávno přidal možnost vytvořit vlastní dotaz už při zakládání transferu a rovnou ukládat agregovaná data do výsledné tabulky. Tento přístup může ušetřit prostor, ale přináší riziko. Pokud totiž zjistíme, že potřebujeme další metriky nebo dimenze, které jsme do původního dotazu nezahrnuli, musíme celý proces nastavovat znovu. Z praktických důvodů je proto často výhodnější stahovat kompletní datovou sadu a rozhodovat se až v BigQuery, jak s ní budeme pracovat.
Sílu Data transfers je vidět i u dalších služeb. Kromě Google Ads a jiných Google platforem lze tímto způsobem napojit i některé externí systémy, například Stripe, PayPal nebo Facebook. A právě u Facebooku stojí za to se zastavit, protože zde se dobře ukazuje, jaké mají nativní konektory výhody a limity.
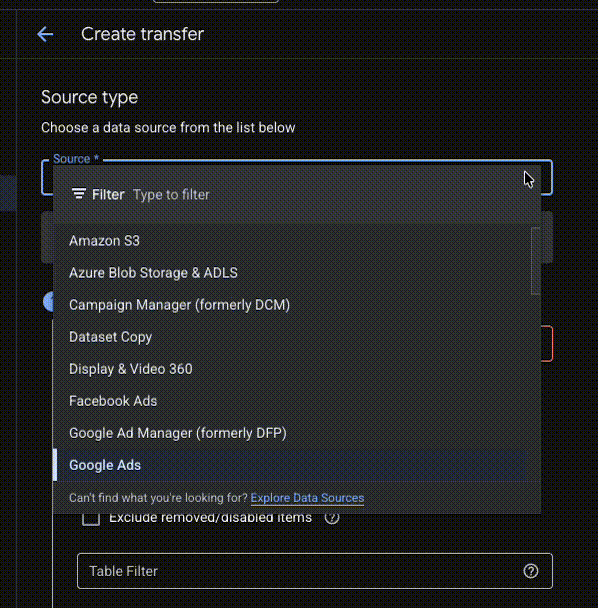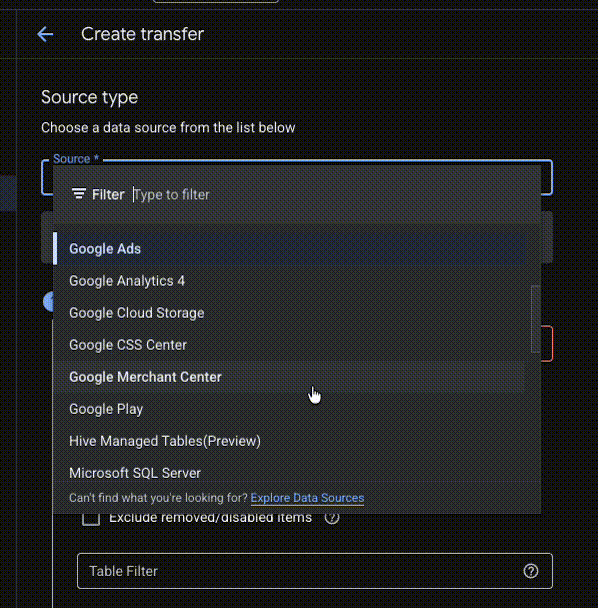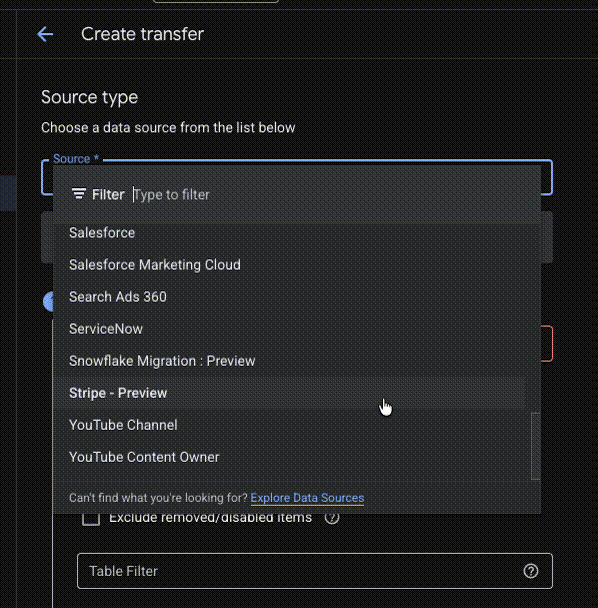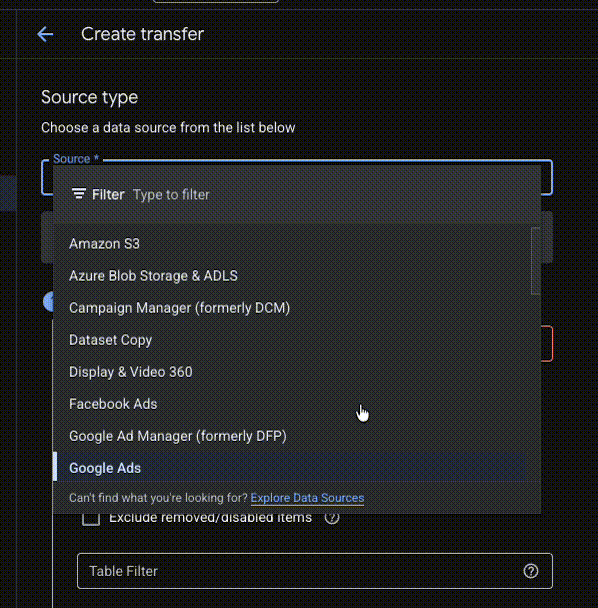
Veškeré služby, které lze nativně napojit přes Data transfers
Ještě donedávna byl nativní Facebook konektor poměrně omezený. Umožňoval sice získat velké množství dat téměř bez námahy, ale zároveň bez možnosti ovlivnit jejich strukturu. Navíc stahoval všechna data propojená s účtem, což bylo problematické, pokud jsme měli v jednom účtu více klientů a potřebovali data jen pro některé z nich. Další komplikací byla nutnost opakované reautorizace API tokenu, která často sváděla k nasazení dlouhodobého tokenu, což z bezpečnostního hlediska není ideální řešení.
Situace se však v posledních měsících výrazně zlepšila. Nová verze konektoru umožňuje vybrat, které tabulky, metriky a dimenze chceme stahovat (i když výběr je stále omezený), a hlavně umožňuje omezit stahování pouze na účty, ke kterým token skutečně poskytuje přístup. Zůstává pouze pravidelná nutnost obnovy tokenu, což je u Facebook API standard.
Keboola
Pokud narazíme na platformu, která nemá v GCP vlastní konektor, nebo nám nativní přístup z nějakého důvodu nevyhovuje, jednou z nejpoužívanějších alternativ je Keboola. Nabízí pohodlné prostředí, které v mnoha ohledech připomíná nativní konektory, ale zároveň poskytuje větší flexibilitu a kontrolu nad načítáním dat. Nevýhodou je jednak cena a jednak skutečnost, že přidáváme do našeho technologického stacku další nástroj, o který se musíme starat.
Cenový model Kebooly je založený na spotřebovaných minutách. Na začátku získáte 120 minut a každý měsíc dalších 60. Pokud potřebujete více, lze si další balíček přikoupit za necelých devět dolarů. Je dobré počítat s tím, že pro každý datový tok vytváříme dva transfery – jeden ze zdroje do Kebooly a druhý z Kebooly do BigQuery.
Odměnou je ale široká nabídka konektorů, které nejsou v GCP běžně dostupné. Keboola pokrývá většinu marketingových a e-commerce platforem, jako jsou Bing, Sklik, TikTok, Pinterest, LinkedIn, Heureka, Shoptet či Shopify. Každý z konektorů se může chovat trochu jinak, zejména pokud jde o autorizaci nebo práci s datovými rozsahy, ale Keboola k nim většinou poskytuje přehlednou dokumentaci.
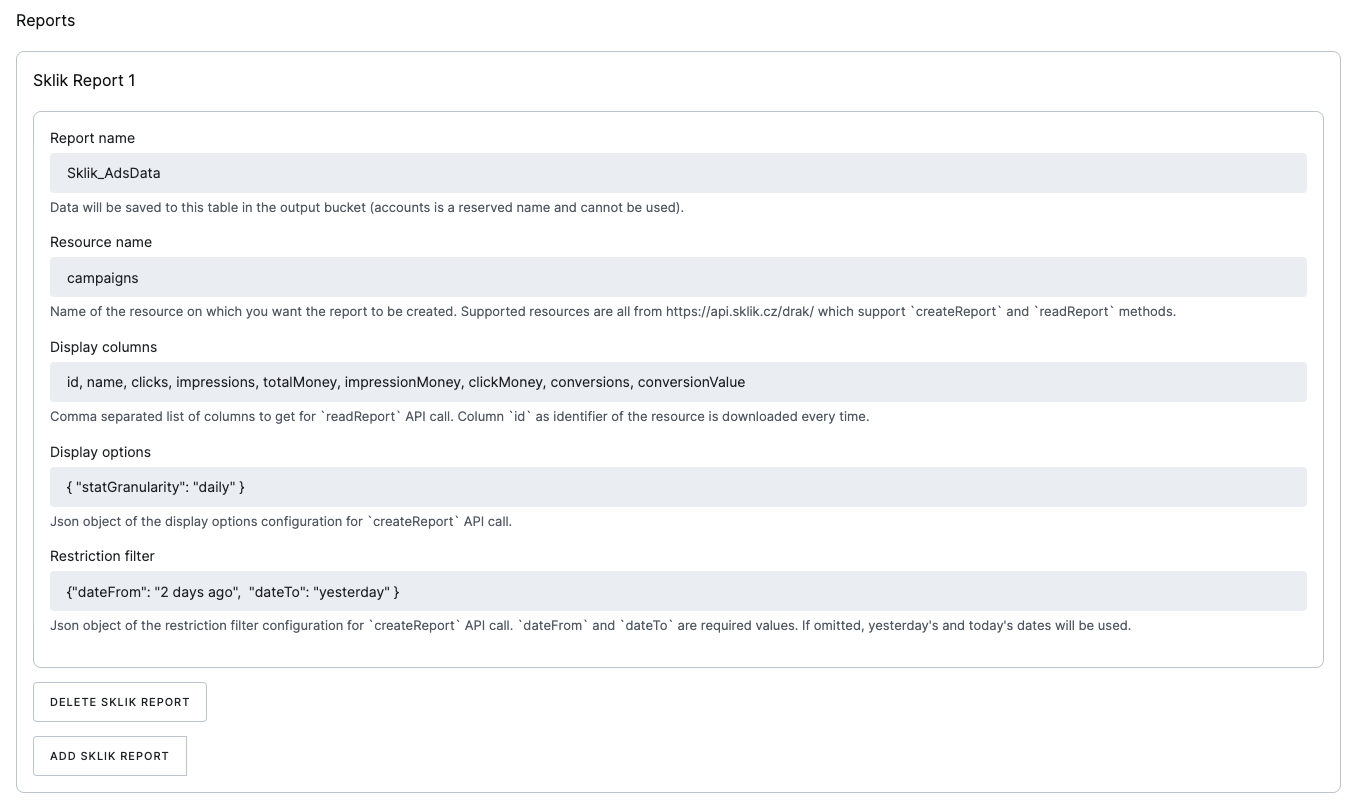
Základní nastavení reportu kampaní z Skliku na denní granularitě
Velkou výhodou je průběžná údržba konektorů. Keboola je aktivně aktualizuje, takže při změnách v API obvykle není potřeba dělat zásahy na naší straně. Dalším plusem je podpora inkrementálního načítání dat přímo do BigQuery, které výrazně snižuje množství redundantních dat a usnadňuje řízení datových pipeline.
💡Keboola ale není jednorožcem v oblasti konektorů a má své alternativy. Za nás můžeme doporučit např. Airbyte, který se vyznačuje vysokou podporou open-source řešení. Jako takový se zaměřuje primárně na konektory (Extract & Load). Keboola oproti tomu poskytuje komplexnější řešení na orchestraci celé pipeline, které může být ale v mnoha případech zbytečné.
Cloud Functions
Keboola však není řešením pro každého. Může být dražší, přidává další nástroj do našeho technologického stacku a ne vždy nám poskytne takovou míru kontroly, kterou potřebujeme. Pokud se nebojíte napsat pár řádků kódu a chcete zůstat v prostředí GCP, pak jsou elegantním řešením Cloud Functions.
Jejich zásadní výhodou je to, že jsou přímou součástí GCP. Běh funkcí se tak účtuje spolu s ostatními cloudovými službami a v praxi jde o velmi nízké náklady. Při denním stahování dat z reklamních systémů se u našich klientů dostáváme na jednotky až nižší desítky korun měsíčně.
Konektor, který stahuje denní kampaňová data z Facebooku
Cloud Functions zároveň poskytují plnou kontrolu nad tím, jak data získáváme a jak s nimi dále pracujeme. Typicky používáme Python, ve kterém určujeme, odkud data stahujeme, jaký dotaz posíláme, jak data validujeme a kam je ukládáme. Tato svoboda ale přináší i vyšší nároky na údržbu. Je potřeba hlídat verze API, změny ve formátu odpovědí i případné limitace jednotlivých endpointů.
Co se týče zdrojů dat, možnosti jsou velmi široké. Většina platforem dnes poskytuje REST API, odkud lze data přímo stahovat. Podobně můžeme pracovat s XML zdroji, jako jsou produktové feedy nebo směnné kurzy ČNB. A pokud má klient vlastní databázi, můžeme data napojit přímo z ní – stačí přístup na úrovni databázového uživatele a vhodný konektor.
Cloud Functions se navíc neomezují jen na stahování dat. Umožňují vytvářet celé automatizační procesy, řídit alerting a odesílat notifikace do projektových nástrojů či e-mailu, spouštět pravidelné kontroly datové kvality nebo obsluhovat další části datové pipeline. Právě jejich flexibilita je důvodem, proč je najdeme prakticky v každém moderním datovém stacku v GCP.
Co preferujeme v igloo 🐧
Výše jsme prošli různé způsoby, jak dostat data do BigQuery, a je přirozené se ptát, zda je některý z nich nejlepší. Odpověď je jednoduchá: není. Každý přístup má své silné i slabé stránky a teprve v konkrétním kontextu začíná dávat smysl, proč se rozhodnout právě pro něj. Nejde tedy o to hledat univerzální řešení, ale vybírat takové, které nejlépe odpovídá tomu, čeho chceme dosáhnout.
U nástrojů od Googlu je situace nejjednodušší. Napojení GA4, Google Ads či Search Console je stabilní, rychlé a řeší prakticky všechno, co od datového přísunu potřebujeme. Pokud existuje nativní konektor, používáme ho téměř bez váhání. S minimálním úsilím získáme data ve vysoké granularitě a bez nutnosti se starat o průběžnou údržbu. Je to pohodlné, funkční a hlavně spolehlivé.
U ostatních zdrojů už přichází rozhodování, které musí zohlednit údržbu, cenu i to, jak technicky otevřený je daný ekosystém. Pokud někdo hledá především pohodlí a předvídatelnost nákladů, dává smysl Keboola. Její konektory fungují stabilně, většinu starostí přebírá za nás a po počátečním nastavení zpravidla není téměř potřeba se jí věnovat. Nevýhodou je cena a skutečnost, že rozšiřuje technologický stack o další nástroj, který musíme mít na radaru. Tam, kde už Keboola běží, je volba snadná. Tam, kde neběží, je to vždy o zvážení kompromisu mezi pohodlím a náklady.
Cloud Functions představují opačný pól. Jsou levné, flexibilní a umožňují absolutní kontrolu nad tím, jak data získáváme, validujeme a ukládáme. Cena provozu je zanedbatelná a v prostředí GCP se vše chová konzistentně. Na druhou stranu vyžadují určitou míru technické zralosti: je potřeba hlídat verze API, reagovat na změny datových struktur nebo řešit neočekávané pády konektorů. Někdy je to práce navíc, ale často je to právě ta práce, která nám umožní řešení přizpůsobit přesně tomu, co klient skutečně potřebuje.
A jaký přístup tedy v igloonetu upřednostňujeme? Nejprve využijeme všechno, co Google nabízí nativně. Pokud klient používá Keboolu, rádi na ni navážeme. A ve všech ostatních situacích volíme Cloud Functions, protože nám dávají možnost reagovat rychle, udržet plnou kontrolu nad datovou pipeline a nebýt závislí na omezeních žádného externího konektoru. Implementace skrze Cloud Functions závisí rovněž na „mainstreamovosti“ nástroje – pokud reklamní nástroj či databázi využívá většina klientů, napojení a následná údržba je jednodušší a levnější. U okrajových nástrojů volíme zpravidla jiná řešení (např. Keboola).
A na konec – neexistuje jediná správná cesta. Existuje jen taková, která nejlépe podporuje konkrétní cíl práce s daty.